Code
siteinfo <- read_csv("C:/Users/jbaldock/OneDrive - DOI/Documents/USGS/EcoDrought/EcoDrought Working/Data/EcoDrought_SiteInformation.csv")
siteinfo_sp <- st_as_sf(siteinfo, coords = c("long", "lat"), crs = 4326)Purpose: Quantify the effect of interannual variation in climatic conditions (water availability) on spatialy variability in headwater flow regimes.
Site information
siteinfo <- read_csv("C:/Users/jbaldock/OneDrive - DOI/Documents/USGS/EcoDrought/EcoDrought Working/Data/EcoDrought_SiteInformation.csv")
siteinfo_sp <- st_as_sf(siteinfo, coords = c("long", "lat"), crs = 4326)Little g’s (headwater sites)
dat_clean <- read_csv("C:/Users/jbaldock/OneDrive - DOI/Documents/USGS/EcoDrought/EcoDrought Working/EcoDrought-Analysis/Qualitative/LittleG_data_clean.csv")Big G’s (reference gages)
dat_clean_big <- read_csv("C:/Users/jbaldock/OneDrive - DOI/Documents/USGS/EcoDrought/EcoDrought Working/EcoDrought-Analysis/Qualitative/BigG_data_clean.csv")Water availability. In western, snowmelt-dominated basins, annual (water year) total yield is strongly related to summer total yield. But in eastern, rain-dominated basins, the relationship is much weaker, suggesting “faster” response to climate forcing in rain-dominated basins. Use total summer yield (percentile) as metric of interannual variation in water availability.
wateravail <- read_csv("C:/Users/jbaldock/OneDrive - DOI/Documents/USGS/EcoDrought/EcoDrought Working/EcoDrought-Analysis/Qualitative/BigG_wateravailability_annual.csv") %>%
filter(!is.na(totalyield), !is.na(totalyield_sum)) %>%
group_by(site_name) %>%
mutate(tyz_perc = percentile(totalyield_z),
tyz_sum_perc = percentile(totalyield_sum_z)) %>%
mutate(tyz_perc = ifelse(is.na(tyz_perc), 0, tyz_perc),
tyz_sum_perc = ifelse(is.na(tyz_sum_perc), 0, tyz_sum_perc))
wateravail %>%
filter(basin != "Piney River") %>%
mutate(basin = ifelse(basin == "Shields River", "Yellowstone River", basin)) %>%
mutate(basin = factor(basin, levels = c("West Brook", "Staunton River", "Paine Run", "Flathead", "Yellowstone River", "Snake River", "Donner Blitzen"))) %>%
ggplot(aes(x = tyz_perc, y = tyz_sum_perc)) +
geom_point() +
geom_smooth(method = "lm") +
xlab("Total annual yield (percentile)") + ylab("Total summer yield (percentile)") +
facet_wrap(~basin) + theme_bw()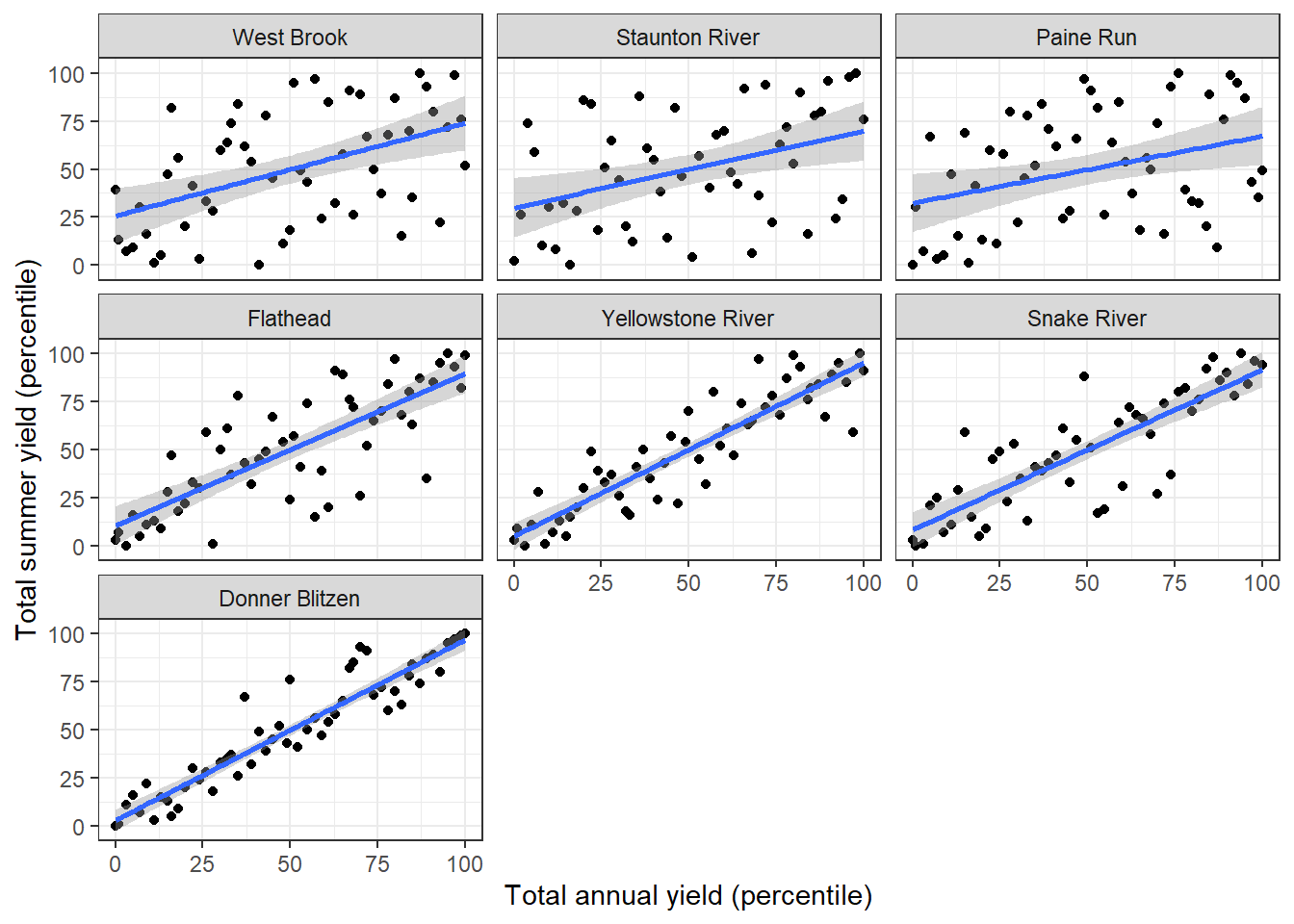
Order sites
wborder <- c("West Brook NWIS", "West Brook Lower", "Mitchell Brook", "Jimmy Brook", "Obear Brook Lower", "West Brook Upper", "West Brook Reservoir", "Sanderson Brook", "Avery Brook", "West Whately Brook")
paineorder <- c("Paine Run 10", "Paine Run 08", "Paine Run 07", "Paine Run 06", "Paine Run 02", "Paine Run 01")
stauntorder <- c("Staunton River 10", "Staunton River 09", "Staunton River 07", "Staunton River 06", "Staunton River 03", "Staunton River 02")
flatorder <- c("BigCreekLower", "LangfordCreekLower", "LangfordCreekUpper", "Big Creek NWIS", "BigCreekUpper", "HallowattCreekLower", "NicolaCreek", "WernerCreek", "Hallowat Creek NWIS", "CoalCreekLower", "CycloneCreekLower", "CycloneCreekMiddle", "CycloneCreekUpper", "CoalCreekMiddle", "CoalCreekNorth", "CoalCreekHeadwaters", "McGeeCreekLower", "McGeeCreekTrib", "McGeeCreekUpper")
yellorder <- c("Shields River Valley Ranch", "Deep Creek", "Crandall Creek", "Buck Creek", "Dugout Creek", "Shields River ab Dugout", "Lodgepole Creek", "EF Duck Creek be HF", "EF Duck Creek ab HF", "Henrys Fork")
snakeorder <- c("Spread Creek Dam", "Rock Creek", "NF Spread Creek Lower", "NF Spread Creek Upper", "Grizzly Creek", "SF Spread Creek Lower", "Grouse Creek", "SF Spread Creek Upper", "Leidy Creek Mouth")
donnerorder <- c("Fish Creek NWIS", "Donner Blitzen ab Fish NWIS", "Donner Blitzen nr Burnt Car NWIS", "Donner Blitzen ab Indian NWIS")Get catchment shapefiles
sheds_list <- list()
myfiles <- list.files(path = "C:/Users/jbaldock/OneDrive - DOI/Documents/USGS/EcoDrought/EcoDrought Working/EcoDrought-Analysis/Watershed Delineation/Watersheds/", pattern = ".shp")
for (i in 1:length(myfiles)) {
sheds_list[[i]] <- st_read(paste("C:/Users/jbaldock/OneDrive - DOI/Documents/USGS/EcoDrought/EcoDrought Working/EcoDrought-Analysis/Watershed Delineation/Watersheds/", myfiles[i], sep = ""))
}
sheds <- do.call(rbind, sheds_list) %>%
mutate(site_id = ifelse(site_id == "SP01", "SP07", ifelse(site_id == "SP07", "SP01", site_id))) %>%
left_join(siteinfo)
#mapview(sheds %>% arrange(desc(area_sqmi)), alpha.regions = 0.2)Plot maps of median summer flow across years/networks
bas <- "West Brook"
orderr <- wborder
wtryrs <- c(2020:2024)
# sheds and network
mysheds <- vect("C:/Users/jbaldock/OneDrive - DOI/Documents/USGS/EcoDrought/EcoDrought Working/EcoDrought-Analysis/Watershed Delineation/Watersheds/Mass_Watersheds.shp")
mysheds <- mysheds[mysheds$site_id == "WBR",]
mynet <- vect("C:/Users/jbaldock/OneDrive - DOI/Documents/USGS/EcoDrought/EcoDrought Working/EcoDrought-Analysis/Watershed Delineation/Streams/Mass_Streams.shp")
crs(mynet) <- crs(mysheds)
mynet <- crop(mynet, mysheds)
# get lakes
lakes <- get_waterbodies(AOI = siteinfo_sp %>% filter(site_name == "West Brook NWIS"), buffer = 10000)
lakes <- lakes %>% filter(gnis_name %in% c("Northampton Reservoir Upper", "Northampton Reservoir"))
#st_write(lakes, "C:/Users/jbaldock/OneDrive - DOI/Documents/USGS/EcoDrought/EcoDrought Working/Study area maps/lakes/lakes_WestBrook.shp")
# little g points
mylittleg <- siteinfo_sp %>% filter(site_name %in% wborder) %>% mutate(site_name = factor(site_name, levels = wborder))
# filter data
tempdat <- dat_clean %>%
filter(basin == bas, !is.na(logYield), Month %in% c(7:9)) %>%
mutate(site_name = factor(site_name, levels = orderr))
nsites <- length(unique(tempdat$site_name))
tempdat_big <- dat_clean_big %>% filter(basin == bas, !is.na(logYield), Month %in% c(7:9))
# calculate variability for reference gage
varbig <- tempdat_big %>%
group_by(WaterYear) %>%
summarize(bigrange = range(logYield)[2]-range(logYield)[1],
bigsd = sd(logYield),
bigvar = var(logYield)) %>%
ungroup()
# calculate total summer water availability from reference gage
#summerflow <- tempdat_big %>% group_by(WaterYear) %>% summarize(summeryield = sum(Yield_mm), summeryield_log = log(sum(Yield_mm))) %>% ungroup()
#wateravail2 <- wateravail %>% select(basin, WaterYear, totalyield, totalyield_z)
# calculate relative variation
pedat <- tempdat %>%
group_by(basin, WaterYear) %>%
summarize(nsites = length(unique(site_name)),
littlerange = range(logYield)[2]-range(logYield)[1],
littlesd = sd(logYield),
littlevar = var(logYield)) %>%
ungroup() %>%
left_join(varbig) %>%
mutate(pe_range = ((littlerange-bigrange)/bigrange),
pe_sd = ((littlesd-bigsd)/bigsd),
pe_var = ((littlevar-bigvar)/bigvar)) %>%
left_join(wateravail %>% select(basin, WaterYear, totalyield, totalyield_z, totalyield_sum, totalyield_sum_z, tyz_perc, tyz_sum_perc)) %>%
filter(WaterYear %in% wtryrs) %>%
mutate(wylab = substr(WaterYear, 3, 4)) %>%
arrange(totalyield_sum_z)
# calculate annual median summer flow
annmed <- tempdat %>%
#filter(WaterYear %in% c(lowyr, highyr)) %>%
group_by(site_name, WaterYear) %>%
summarize(medlogYield = median(logYield, na.rm = TRUE)) %>%
ungroup()
# calculate long-term median of summer median flow, to center color scheme
annmed_big <- tempdat_big %>%
group_by(site_name, WaterYear) %>%
summarize(medlogYield = median(logYield, na.rm = TRUE)) %>%
ungroup()
annmed_big <- median(annmed_big$medlogYield)
# arrange years by total annual yield
wtryrs_arranged <- as.numeric(unlist(pedat %>% select(WaterYear)))
# plot it
plotlist_wb <- list()
for(i in 1:length(wtryrs_arranged)) {
mylittleg <- siteinfo_sp %>% filter(site_name %in% orderr) %>% left_join(annmed %>% filter(WaterYear == wtryrs_arranged[i]))
mylittleg_sheds <- sheds %>% filter(site_name %in% orderr) %>% left_join(annmed %>% filter(WaterYear == wtryrs_arranged[i])) %>% arrange(desc(area_sqmi))
plotlist_wb[[i]] <- local({
i <- i
ggplot() +
geom_sf(data = st_as_sf(mysheds), color = "black", fill = "white", linewidth = 0.4) +
geom_sf(data = mylittleg_sheds, aes(fill = medlogYield), color = "black") +
scale_fill_viridis(option = "G", direction = 1, limits = range(annmed$medlogYield), na.value = "grey") +
#scale_fill_gradientn(colours = rev(hcl.colors(100, "Zissou1")), limits = range(annmed$medlogYield), na.value = "grey") +
#scale_fill_gradientn(colours = cet_pal(100, name = "l16"), limits = range(annmed$medlogYield), na.value = "grey") +
geom_sf(data = st_as_sf(mynet), color = "white", linewidth = 1, lineend = "round") +
geom_sf(data = st_as_sf(mynet), color = "royalblue4", linewidth = 0.6, lineend = "round") +
geom_sf(data = lakes, color = "white", fill = "lightskyblue1", linewidth = 0.7) +
geom_sf(data = lakes, color = "royalblue4", fill = "lightskyblue1", linewidth = 0.5) +
geom_sf(data = mylittleg, shape = 21, fill = "white", size = 2) +
labs(fill = "Median\nsummer\nlog(Yield)") + #annotation_scale() +
coord_sf(xlim = range(st_coordinates(mylittleg_sheds)[,1]), ylim = range(st_coordinates(mylittleg_sheds)[,2])) +
theme_bw() + theme(axis.title.x = element_blank(), axis.title.y = element_blank(), legend.position = "none", axis.text = element_blank()) +
annotate("label", x = Inf, y = Inf, label = paste(pedat$WaterYear[i], " (", pedat$tyz_sum_perc[i], "%)", sep = ""), vjust = 1.15, hjust = 1.05, size = 5)})
}
ggarrange(plotlist = plotlist_wb, common.legend = TRUE, legend = "right")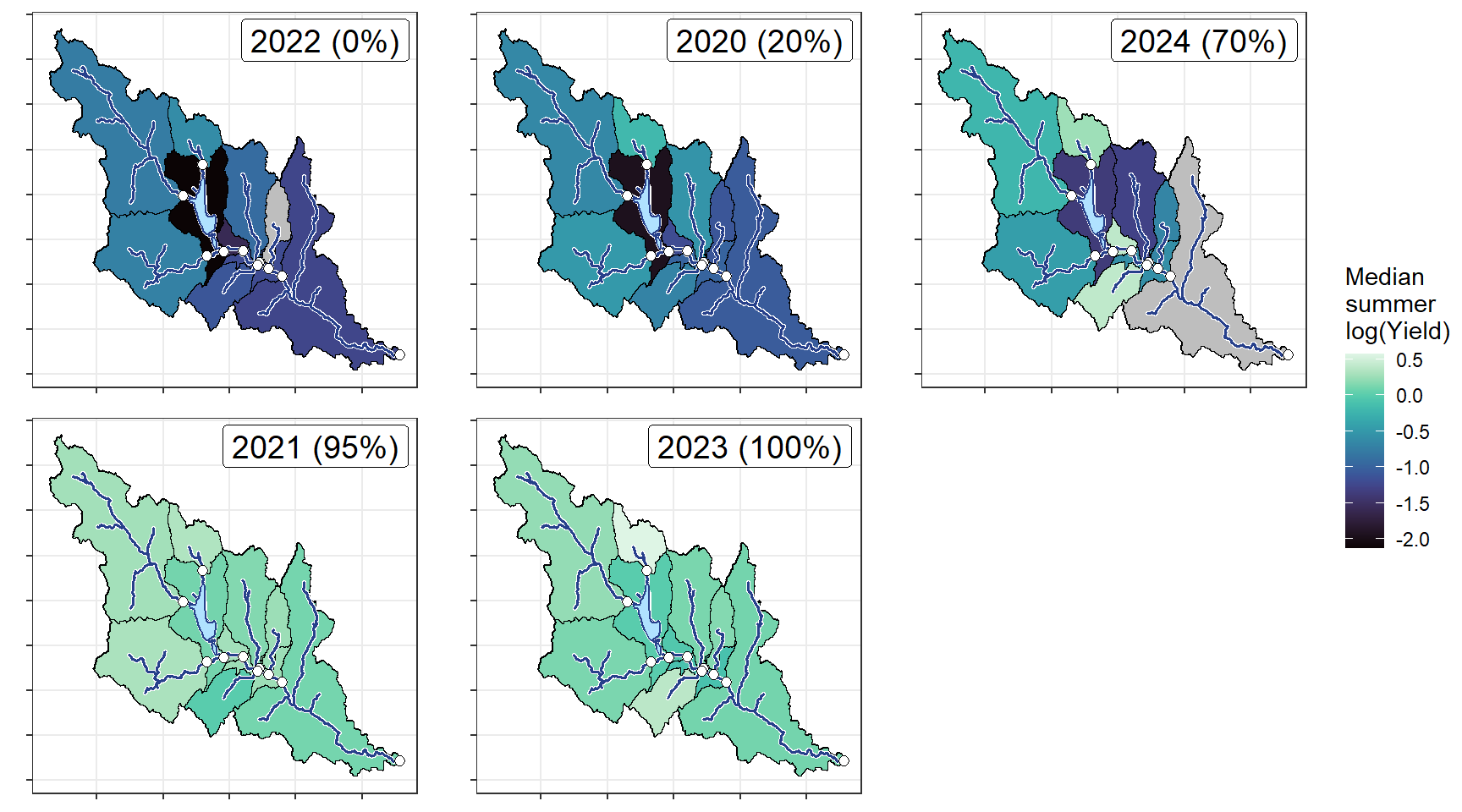
bas <- "Paine Run"
orderr <- paineorder
wtryrs <- c(2019:2022)
mysheds <- vect("C:/Users/jbaldock/OneDrive - DOI/Documents/USGS/EcoDrought/EcoDrought Working/EcoDrought-Analysis/Watershed Delineation/Watersheds/Shen_Watersheds.shp")
mysheds <- mysheds[mysheds$site_id == "PA_10FL",]
mynet <- vect("C:/Users/jbaldock/OneDrive - DOI/Documents/USGS/EcoDrought/EcoDrought Working/EcoDrought-Analysis/Watershed Delineation/Streams/Shen_Streams.shp")
crs(mynet) <- crs(mysheds)
mynet <- crop(mynet, mysheds)
# hillshade
myrast <- rast("C:/Users/jbaldock/OneDrive - DOI/Documents/USGS/EcoDrought/EcoDrought Working/Data/Spatial data/Elevation/Shenandoah_DEM_10m_nc.tif")
myrast <- mask(crop(myrast, mysheds), mysheds)
slo <- terrain(myrast, "slope", unit = "radians")
asp <- terrain(myrast, "aspect", unit = "radians")
hill <- shade(slope = slo, aspect = asp, angle = 40, direction = 270)
hilldf <- as.data.frame(hill, xy = TRUE)
# little g points
mylittleg <- siteinfo_sp %>% filter(site_name %in% orderr)
# filter data
tempdat <- dat_clean %>%
filter(basin == bas, !is.na(logYield), Month %in% c(7:9)) %>%
mutate(site_name = factor(site_name, levels = orderr))
nsites <- length(unique(tempdat$site_name))
tempdat_big <- dat_clean_big %>% filter(basin == bas, !is.na(logYield), Month %in% c(7:9), WaterYear %in% unique(tempdat$WaterYear))
# calculate variability for reference gage
varbig <- tempdat_big %>%
group_by(WaterYear) %>%
summarize(bigrange = range(logYield)[2]-range(logYield)[1],
bigsd = sd(logYield),
bigvar = var(logYield)) %>%
ungroup()
# calculate total summer water availability from reference gage
#summerflow <- tempdat_big %>% group_by(WaterYear) %>% summarize(summeryield = sum(Yield_mm), summeryield_log = log(sum(Yield_mm))) %>% ungroup()
#wateravail2 <- wateravail %>% select(basin, WaterYear, totalyield, totalyield_z)
# calculate relative variation
pedat <- tempdat %>%
group_by(basin, WaterYear) %>%
summarize(nsites = length(unique(site_name)),
littlerange = range(logYield)[2]-range(logYield)[1],
littlesd = sd(logYield),
littlevar = var(logYield)) %>%
ungroup() %>%
left_join(varbig) %>%
mutate(pe_range = ((littlerange-bigrange)/bigrange),
pe_sd = ((littlesd-bigsd)/bigsd),
pe_var = ((littlevar-bigvar)/bigvar)) %>%
left_join(wateravail %>% select(basin, WaterYear, totalyield, totalyield_z, totalyield_sum, totalyield_sum_z, tyz_perc, tyz_sum_perc)) %>%
filter(WaterYear %in% wtryrs) %>%
mutate(wylab = substr(WaterYear, 3, 4)) %>%
arrange(totalyield_sum_z)
# calculate annual median summer flow
annmed <- tempdat %>%
#filter(WaterYear %in% c(lowyr, highyr)) %>%
group_by(site_name, WaterYear) %>%
summarize(medlogYield = median(logYield, na.rm = TRUE)) %>%
ungroup()
# arrange years by total annual yield
wtryrs_arranged <- as.numeric(unlist(pedat %>% select(WaterYear)))
# plot it
plotlist_pa <- list()
for(i in 1:length(wtryrs_arranged)) {
mylittleg <- siteinfo_sp %>% filter(site_name %in% orderr) %>% left_join(annmed %>% filter(WaterYear == wtryrs_arranged[i]))
mylittleg_sheds <- sheds %>% filter(site_name %in% orderr) %>% left_join(annmed %>% filter(WaterYear == wtryrs_arranged[i])) %>% arrange(desc(area_sqmi))
plotlist_pa[[i]] <- local({
i <- i
ggplot() +
geom_sf(data = st_as_sf(mysheds), color = "black", fill = "white", linewidth = 0.4) +
geom_sf(data = mylittleg_sheds, aes(fill = medlogYield), color = "black") +
scale_fill_viridis(option = "G", direction = 1, limits = range(annmed$medlogYield), na.value = "grey") +
geom_sf(data = st_as_sf(mynet), color = "white", linewidth = 1, lineend = "round") +
geom_sf(data = st_as_sf(mynet), color = "royalblue4", linewidth = 0.6, lineend = "round") +
geom_sf(data = mylittleg, shape = 21, fill = "white", size = 2) +
labs(fill = "Median\nsummer\nlog(Yield)") + #annotation_scale() +
coord_sf(xlim = range(st_coordinates(mylittleg_sheds)[,1]), ylim = range(st_coordinates(mylittleg_sheds)[,2])) +
theme_bw() + theme(axis.title.x = element_blank(), axis.title.y = element_blank(), legend.position = "none", axis.text = element_blank()) +
annotate("label", x = -Inf, y = Inf, label = paste(pedat$WaterYear[i], " (", pedat$tyz_sum_perc[i], "%)", sep = ""), vjust = 1.15, hjust = -0.05, size = 5)})
}
ggarrange(plotlist = plotlist_pa, common.legend = TRUE, legend = "right")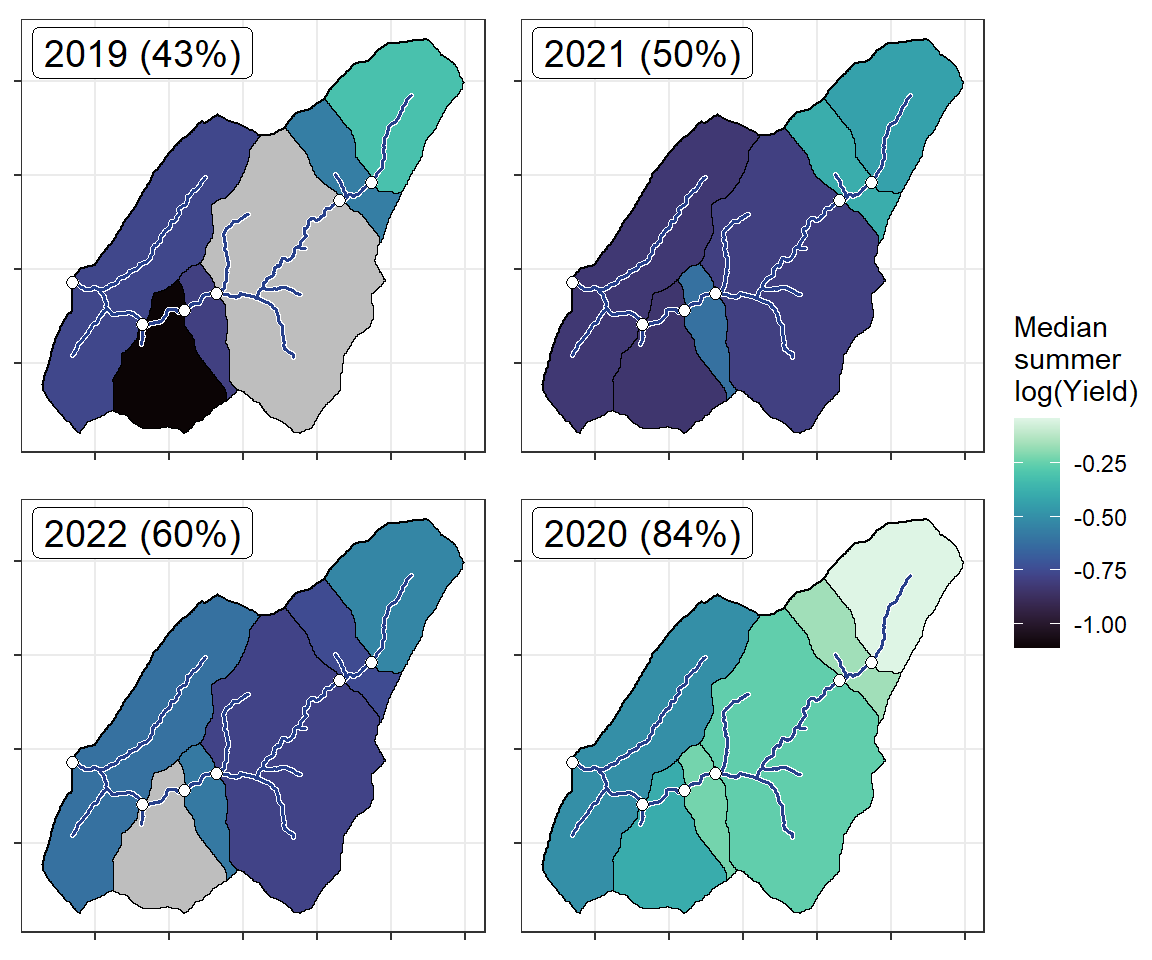
bas <- "Staunton River"
orderr <- stauntorder
wtryrs <- c(2019:2022)
mysheds <- vect("C:/Users/jbaldock/OneDrive - DOI/Documents/USGS/EcoDrought/EcoDrought Working/EcoDrought-Analysis/Watershed Delineation/Watersheds/Shen_Watersheds.shp")
mysheds <- mysheds[mysheds$site_id == "SR_10FL",]
mynet <- vect("C:/Users/jbaldock/OneDrive - DOI/Documents/USGS/EcoDrought/EcoDrought Working/EcoDrought-Analysis/Watershed Delineation/Streams/Shen_Streams.shp")
crs(mynet) <- crs(mysheds)
mynet <- crop(mynet, mysheds)
# little g points
mylittleg <- siteinfo_sp %>% filter(site_name %in% orderr)
# filter data
tempdat <- dat_clean %>%
filter(basin == bas, !is.na(logYield), Month %in% c(7:9)) %>%
mutate(site_name = factor(site_name, levels = orderr))
nsites <- length(unique(tempdat$site_name))
tempdat_big <- dat_clean_big %>% filter(basin == bas, !is.na(logYield), Month %in% c(7:9), WaterYear %in% unique(tempdat$WaterYear))
# calculate variability for reference gage
varbig <- tempdat_big %>%
group_by(WaterYear) %>%
summarize(bigrange = range(logYield)[2]-range(logYield)[1],
bigsd = sd(logYield),
bigvar = var(logYield)) %>%
ungroup()
# calculate total summer water availability from reference gage
#summerflow <- tempdat_big %>% group_by(WaterYear) %>% summarize(summeryield = sum(Yield_mm), summeryield_log = log(sum(Yield_mm))) %>% ungroup()
#wateravail2 <- wateravail %>% select(basin, WaterYear, totalyield, totalyield_z)
# calculate relative variation
pedat <- tempdat %>%
group_by(basin, WaterYear) %>%
summarize(nsites = length(unique(site_name)),
littlerange = range(logYield)[2]-range(logYield)[1],
littlesd = sd(logYield),
littlevar = var(logYield)) %>%
ungroup() %>%
left_join(varbig) %>%
mutate(pe_range = ((littlerange-bigrange)/bigrange),
pe_sd = ((littlesd-bigsd)/bigsd),
pe_var = ((littlevar-bigvar)/bigvar)) %>%
left_join(wateravail %>% select(basin, WaterYear, totalyield, totalyield_z, totalyield_sum, totalyield_sum_z, tyz_perc, tyz_sum_perc)) %>%
filter(WaterYear %in% wtryrs) %>%
mutate(wylab = substr(WaterYear, 3, 4)) %>%
arrange(totalyield_sum_z)
# calculate annual median summer flow
annmed <- tempdat %>%
#filter(WaterYear %in% c(lowyr, highyr)) %>%
group_by(site_name, WaterYear) %>%
summarize(medlogYield = median(logYield, na.rm = TRUE)) %>%
ungroup()
# arrange years by total annual yield
wtryrs_arranged <- as.numeric(unlist(pedat %>% select(WaterYear)))
# plot it
plotlist_st <- list()
for(i in 1:length(wtryrs_arranged)) {
mylittleg <- siteinfo_sp %>% filter(site_name %in% orderr) %>% left_join(annmed %>% filter(WaterYear == wtryrs_arranged[i]))
mylittleg_sheds <- sheds %>% filter(site_name %in% orderr) %>% left_join(annmed %>% filter(WaterYear == wtryrs_arranged[i])) %>% arrange(desc(area_sqmi))
plotlist_st[[i]] <- local({
i <- i
ggplot() +
geom_sf(data = st_as_sf(mysheds), color = "black", fill = "white", linewidth = 0.4) +
geom_sf(data = mylittleg_sheds, aes(fill = medlogYield), color = "black") +
scale_fill_viridis(option = "G", direction = 1, limits = range(annmed$medlogYield), na.value = "grey") +
geom_sf(data = st_as_sf(mynet), color = "white", linewidth = 1, lineend = "round") +
geom_sf(data = st_as_sf(mynet), color = "royalblue4", linewidth = 0.6, lineend = "round") +
geom_sf(data = mylittleg, shape = 21, fill = "white", size = 2) +
labs(fill = "Median\nsummer\nlog(Yield)") + #annotation_scale() +
coord_sf(xlim = range(st_coordinates(mylittleg_sheds)[,1]), ylim = range(st_coordinates(mylittleg_sheds)[,2])) +
theme_bw() + theme(axis.title.x = element_blank(), axis.title.y = element_blank(), legend.position = "none", axis.text = element_blank()) +
annotate("label", x = Inf, y = Inf, label = paste(pedat$WaterYear[i], " (", pedat$tyz_sum_perc[i], "%)", sep = ""), vjust = 1.15, hjust = 1.05, size = 5)})
}
ggarrange(plotlist = plotlist_st, common.legend = TRUE, legend = "right")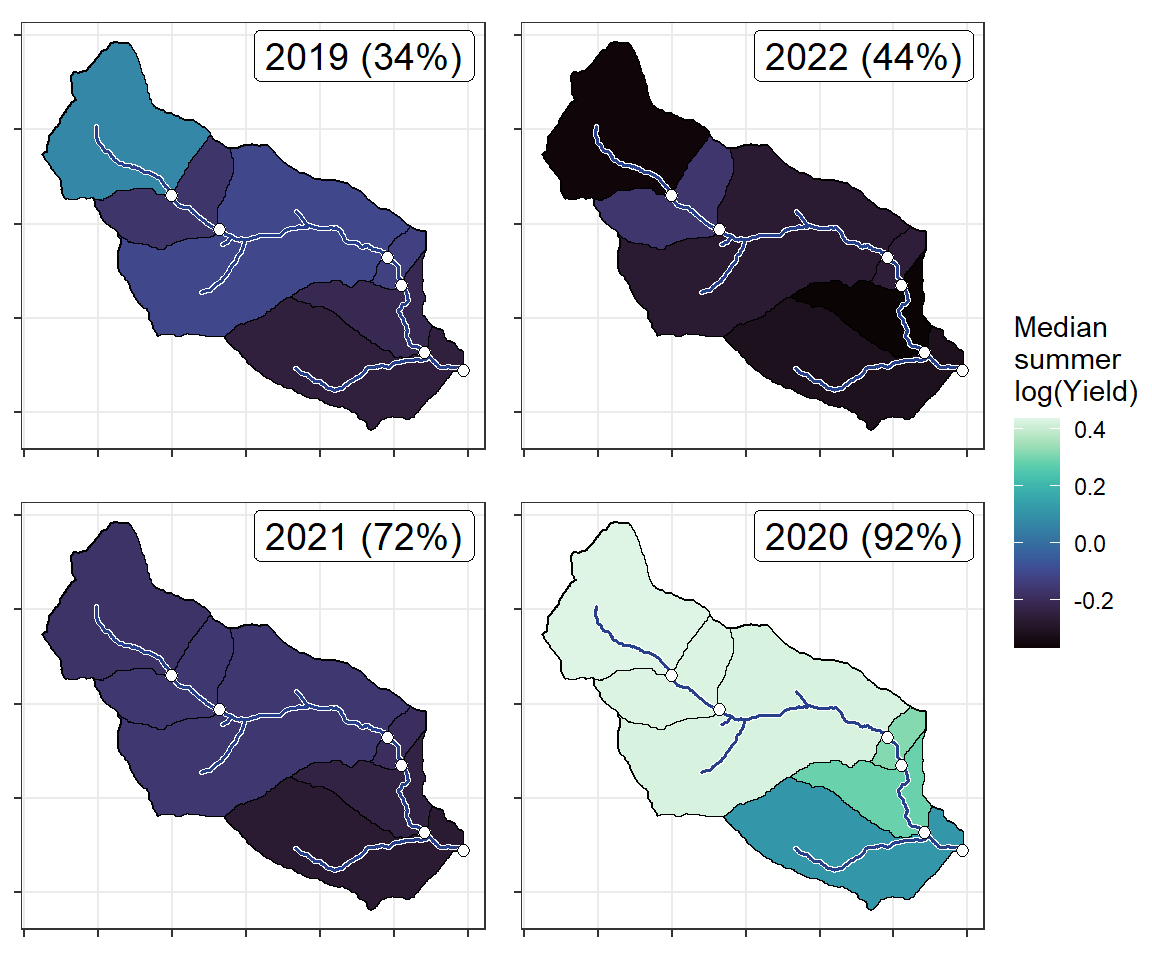
bas <- "Flathead"
orderr <- flatorder
wtryrs <- c(2018:2024)
mysheds <- vect("C:/Users/jbaldock/OneDrive - DOI/Documents/USGS/EcoDrought/EcoDrought Working/EcoDrought-Analysis/Watershed Delineation/Watersheds/Flat_Watersheds.shp")
mysheds <- mysheds[mysheds$site_id == "NFF",]
mynet <- vect("C:/Users/jbaldock/OneDrive - DOI/Documents/USGS/EcoDrought/EcoDrought Working/EcoDrought-Analysis/Watershed Delineation/Streams/Flat_Streams.shp")
crs(mynet) <- crs(mysheds)
mynet <- crop(mynet, mysheds)
# get lakes
lakes <- get_waterbodies(AOI = siteinfo_sp %>% filter(site_name == "North Fork Flathead River NWIS"), buffer = 100000)
lakes <- st_transform(lakes, crs(mysheds))
lakes <- st_intersection(lakes, st_as_sf(mysheds))
lakes <- lakes %>% filter(gnis_name %in% c("Moose Lake", "Mud Lake"))
# points
mylittleg <- siteinfo_sp %>% filter(site_name %in% flatorder) %>% mutate(site_name = factor(site_name, levels = flatorder))
st_geometry(mylittleg)[mylittleg$site_name == "BigCreekUpper"] <- st_point(c(-114.31506, 48.57672))
st_geometry(mylittleg)[mylittleg$site_name == "HallowattCreekLower"] <- st_point(c(-114.31914, 48.57256))
# filter data
tempdat <- dat_clean %>%
filter(basin == bas, !is.na(logYield), Month %in% c(7:9)) %>%
mutate(site_name = factor(site_name, levels = orderr))
nsites <- length(unique(tempdat$site_name))
tempdat_big <- dat_clean_big %>% filter(basin == bas, !is.na(logYield), Month %in% c(7:9), WaterYear %in% unique(tempdat$WaterYear))
# calculate variability for reference gage
varbig <- tempdat_big %>%
group_by(WaterYear) %>%
summarize(bigrange = range(logYield)[2]-range(logYield)[1],
bigsd = sd(logYield),
bigvar = var(logYield)) %>%
ungroup()
# calculate total summer water availability from reference gage
#summerflow <- tempdat_big %>% group_by(WaterYear) %>% summarize(summeryield = sum(Yield_mm), summeryield_log = log(sum(Yield_mm))) %>% ungroup()
#wateravail2 <- wateravail %>% select(basin, WaterYear, totalyield, totalyield_z)
# calculate relative variation
pedat <- tempdat %>%
group_by(basin, WaterYear) %>%
summarize(nsites = length(unique(site_name)),
littlerange = range(logYield)[2]-range(logYield)[1],
littlesd = sd(logYield),
littlevar = var(logYield)) %>%
ungroup() %>%
left_join(varbig) %>%
mutate(pe_range = ((littlerange-bigrange)/bigrange),
pe_sd = ((littlesd-bigsd)/bigsd),
pe_var = ((littlevar-bigvar)/bigvar)) %>%
left_join(wateravail %>% select(basin, WaterYear, totalyield, totalyield_z, totalyield_sum, totalyield_sum_z, tyz_perc, tyz_sum_perc)) %>%
filter(WaterYear %in% wtryrs) %>%
mutate(wylab = substr(WaterYear, 3, 4)) %>%
arrange(totalyield_sum_z)
# calculate annual median summer flow
annmed <- tempdat %>%
#filter(WaterYear %in% c(lowyr, highyr)) %>%
group_by(site_name, WaterYear) %>%
summarize(medlogYield = median(logYield, na.rm = TRUE)) %>%
ungroup()
# arrange years by total annual yield
wtryrs_arranged <- as.numeric(unlist(pedat %>% select(WaterYear)))
# plot it
plotlist_fl <- list()
for(i in 1:length(wtryrs_arranged)) {
mylittleg <- siteinfo_sp %>% filter(site_name %in% orderr) %>% left_join(annmed %>% filter(WaterYear == wtryrs_arranged[i]))
mylittleg_sheds <- sheds %>% filter(site_name %in% orderr) %>% left_join(annmed %>% filter(WaterYear == wtryrs_arranged[i])) %>% arrange(desc(area_sqmi))
plotlist_fl[[i]] <- local({
i <- i
ggplot() +
geom_sf(data = st_as_sf(mysheds), color = "black", fill = "white", linewidth = 0.4) +
geom_sf(data = mylittleg_sheds, aes(fill = medlogYield), color = "black") +
scale_fill_viridis(option = "G", direction = 1, limits = range(annmed$medlogYield), na.value = "grey") +
geom_sf(data = st_as_sf(mynet), color = "white", linewidth = 1, lineend = "round") +
geom_sf(data = st_as_sf(mynet), color = "royalblue4", linewidth = 0.6, lineend = "round") +
geom_sf(data = mylittleg, shape = 21, fill = "white", size = 2) +
labs(fill = "Median\nsummer\nlog(Yield)") + #annotation_scale() +
coord_sf(xlim = range(st_coordinates(mylittleg_sheds)[,1]), ylim = range(st_coordinates(mylittleg_sheds)[,2])) +
theme_bw() + theme(axis.title.x = element_blank(), axis.title.y = element_blank(), legend.position = "none", axis.text = element_blank()) +
annotate("label", x = Inf, y = Inf, label = paste(pedat$WaterYear[i], " (", pedat$tyz_sum_perc[i], "%)", sep = ""), vjust = 1.15, hjust = 1.05, size = 5)})
}
ggarrange(plotlist = plotlist_fl, common.legend = TRUE, legend = "right")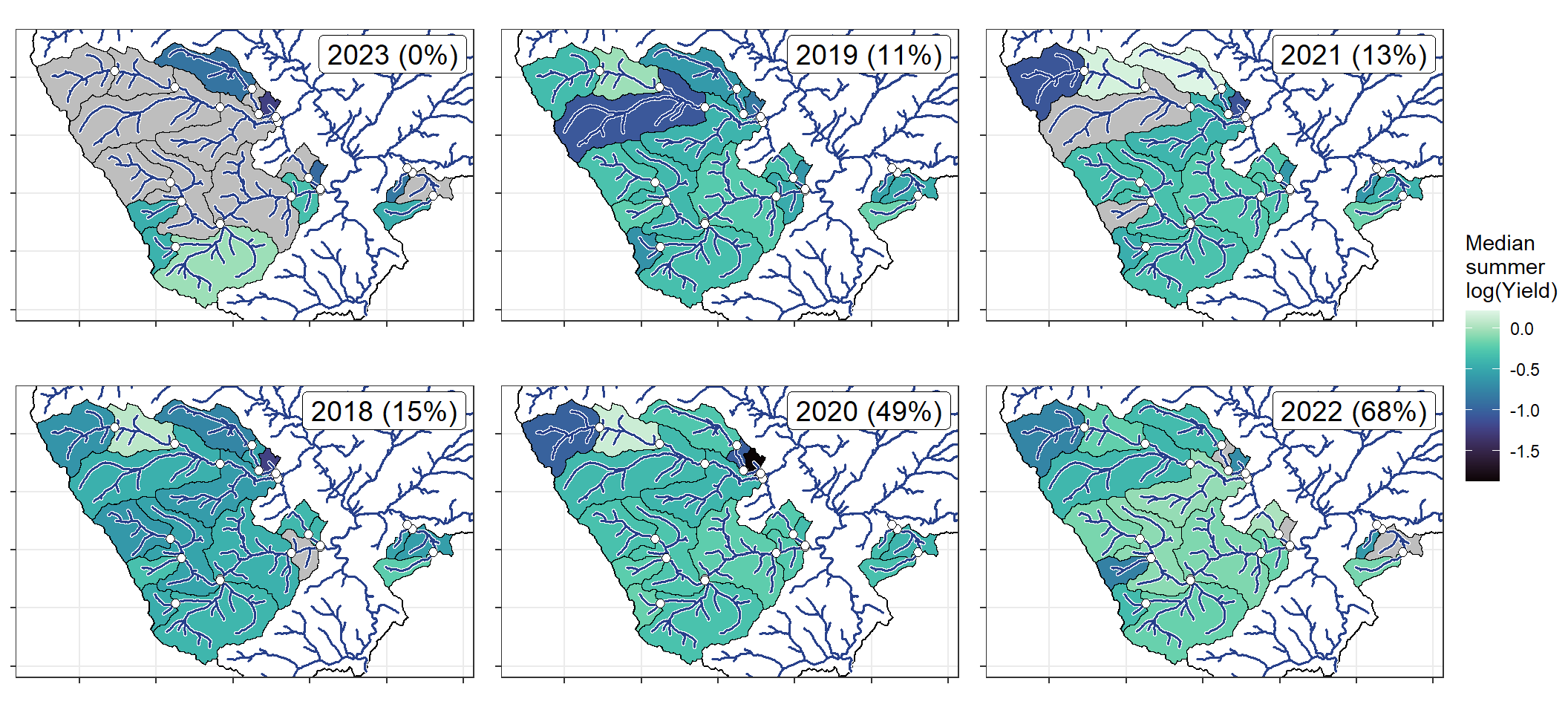
bas <- "Shields River"
orderr <- yellorder
wtryrs <- c(2016:2020,2022:2024)
mysheds <- vect("C:/Users/jbaldock/OneDrive - DOI/Documents/USGS/EcoDrought/EcoDrought Working/EcoDrought-Analysis/Watershed Delineation/Watersheds/Shields_Watersheds.shp")
mysheds <- mysheds[mysheds$site_id %in% c("SRS", "DU01"),]
mynet <- vect("C:/Users/jbaldock/OneDrive - DOI/Documents/USGS/EcoDrought/EcoDrought Working/EcoDrought-Analysis/Watershed Delineation/Streams/Shields_Streams.shp")
crs(mynet) <- crs(mysheds)
mynet <- crop(mynet, mysheds)
# points
mylittleg <- siteinfo_sp %>% filter(site_name %in% orderr) %>% mutate(site_name = factor(site_name, levels = orderr)) #%>% filter(subbasin != "Duck Creek")
# filter data
tempdat <- dat_clean %>%
filter(basin == bas, !is.na(logYield), Month %in% c(7:9)) %>%
mutate(site_name = factor(site_name, levels = orderr))
nsites <- length(unique(tempdat$site_name))
tempdat_big <- dat_clean_big %>% filter(basin == bas, !is.na(logYield), Month %in% c(7:9), WaterYear %in% unique(tempdat$WaterYear))
# calculate variability for reference gage
varbig <- tempdat_big %>%
group_by(WaterYear) %>%
summarize(bigrange = range(logYield)[2]-range(logYield)[1],
bigsd = sd(logYield),
bigvar = var(logYield)) %>%
ungroup()
# calculate total summer water availability from reference gage
#summerflow <- tempdat_big %>% group_by(WaterYear) %>% summarize(summeryield = sum(Yield_mm), summeryield_log = log(sum(Yield_mm))) %>% ungroup()
#wateravail2 <- wateravail %>% select(basin, WaterYear, totalyield, totalyield_z)
# calculate relative variation
pedat <- tempdat %>%
group_by(basin, WaterYear) %>%
summarize(nsites = length(unique(site_name)),
littlerange = range(logYield)[2]-range(logYield)[1],
littlesd = sd(logYield),
littlevar = var(logYield)) %>%
ungroup() %>%
left_join(varbig) %>%
mutate(pe_range = ((littlerange-bigrange)/bigrange),
pe_sd = ((littlesd-bigsd)/bigsd),
pe_var = ((littlevar-bigvar)/bigvar)) %>%
left_join(wateravail %>% select(basin, WaterYear, totalyield, totalyield_z, totalyield_sum, totalyield_sum_z, tyz_perc, tyz_sum_perc)) %>%
filter(WaterYear %in% wtryrs) %>%
mutate(wylab = substr(WaterYear, 3, 4)) %>%
arrange(totalyield_sum_z)
# calculate annual median summer flow
annmed <- tempdat %>%
#filter(WaterYear %in% c(lowyr, highyr)) %>%
group_by(site_name, WaterYear) %>%
summarize(medlogYield = median(logYield, na.rm = TRUE)) %>%
ungroup()
# arrange years by total annual yield
wtryrs_arranged <- as.numeric(unlist(pedat %>% select(WaterYear)))
# plot it
plotlist_ye <- list()
for(i in 1:length(wtryrs_arranged)) {
mylittleg <- siteinfo_sp %>% filter(site_name %in% orderr) %>% left_join(annmed %>% filter(WaterYear == wtryrs_arranged[i]))
mylittleg_sheds <- sheds %>% filter(site_name %in% orderr) %>% left_join(annmed %>% filter(WaterYear == wtryrs_arranged[i])) %>% arrange(desc(area_sqmi))
plotlist_ye[[i]] <- local({
i <- i
ggplot() +
geom_sf(data = st_as_sf(mysheds), color = "black", fill = "white", linewidth = 0.4) +
geom_sf(data = mylittleg_sheds, aes(fill = medlogYield), color = "black") +
scale_fill_viridis(option = "G", direction = 1, limits = range(annmed$medlogYield), na.value = "grey") +
geom_sf(data = st_as_sf(mynet), color = "white", linewidth = 1, lineend = "round") +
geom_sf(data = st_as_sf(mynet), color = "royalblue4", linewidth = 0.6, lineend = "round") +
geom_sf(data = mylittleg, shape = 21, fill = "white", size = 2) +
labs(fill = "Median\nsummer\nlog(Yield)") + #annotation_scale() +
coord_sf(xlim = range(st_coordinates(mylittleg_sheds)[,1]), ylim = range(st_coordinates(mylittleg_sheds)[,2])) +
theme_bw() + theme(axis.title.x = element_blank(), axis.title.y = element_blank(), legend.position = "none", axis.text = element_blank()) +
annotate("label", x = -Inf, y = -Inf, label = paste(pedat$WaterYear[i], " (", pedat$tyz_sum_perc[i], "%)", sep = ""), vjust = -0.15, hjust = -0.05, size = 5)})
}
ggarrange(plotlist = plotlist_ye, common.legend = TRUE, legend = "right", nrow = 2, ncol = 4)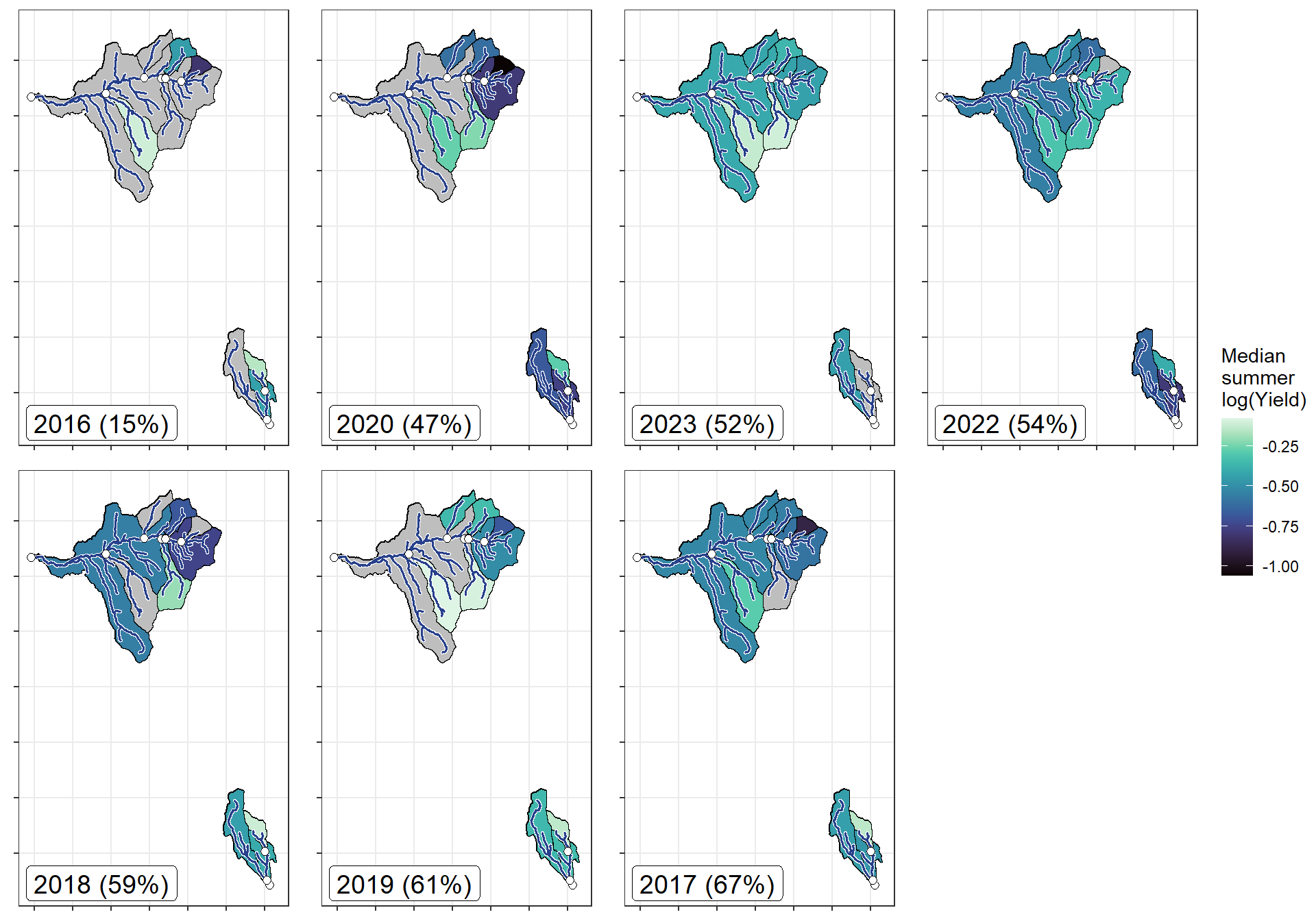
bas <- "Snake River"
orderr <- snakeorder
wtryrs <- c(2016:2024)
mysheds <- vect("C:/Users/jbaldock/OneDrive - DOI/Documents/USGS/EcoDrought/EcoDrought Working/EcoDrought-Analysis/Watershed Delineation/Watersheds/Snake_Watersheds.shp")
mysheds <- mysheds[mysheds$site_id == "SP11",]
mynet <- vect("C:/Users/jbaldock/OneDrive - DOI/Documents/USGS/EcoDrought/EcoDrought Working/EcoDrought-Analysis/Watershed Delineation/Streams/Snake_Streams.shp")
crs(mynet) <- crs(mysheds)
mynet <- crop(mynet, mysheds)
# get lakes
lakes <- get_waterbodies(AOI = siteinfo_sp %>% filter(site_name == "Spread Creek Dam"), buffer = 100000)
lakes <- st_transform(lakes, crs(mysheds))
lakes <- st_intersection(lakes, st_as_sf(mysheds))
lakes <- lakes %>% filter(gnis_name %in% c("Leidy Lake"))
# points
mylittleg <- siteinfo_sp %>% filter(site_name %in% snakeorder) %>% mutate(site_name = factor(site_name, levels = snakeorder))
# edit geometry to reduce overlap
st_geometry(mylittleg)[mylittleg$site_name == "SF Spread Creek Lower NWIS"] <- st_point(c(-110.32226, 43.76118))
st_geometry(mylittleg)[mylittleg$site_name == "NF Spread Creek Lower"] <- st_point(c(-110.3199, 43.766533))
st_geometry(mylittleg)[mylittleg$site_name == "Grizzly Creek"] <- st_point(c(-110.23289, 43.77433))
st_geometry(mylittleg)[mylittleg$site_name == "NF Spread Creek Upper"] <- st_point(c(-110.23405, 43.77227))
st_geometry(mylittleg)[mylittleg$site_name == "SF Spread Creek Upper"] <- st_point(c(-110.31475, 43.73661))
# filter data
tempdat <- dat_clean %>%
filter(basin == bas, !is.na(logYield), Month %in% c(7:9)) %>%
mutate(site_name = factor(site_name, levels = orderr))
nsites <- length(unique(tempdat$site_name))
tempdat_big <- dat_clean_big %>% filter(basin == bas, !is.na(logYield), Month %in% c(7:9), WaterYear %in% unique(tempdat$WaterYear))
# calculate variability for reference gage
varbig <- tempdat_big %>%
group_by(WaterYear) %>%
summarize(bigrange = range(logYield)[2]-range(logYield)[1],
bigsd = sd(logYield),
bigvar = var(logYield)) %>%
ungroup()
# calculate total summer water availability from reference gage
#summerflow <- tempdat_big %>% group_by(WaterYear) %>% summarize(summeryield = sum(Yield_mm), summeryield_log = log(sum(Yield_mm))) %>% ungroup()
#wateravail2 <- wateravail %>% select(basin, WaterYear, totalyield, totalyield_z)
# calculate relative variation
pedat <- tempdat %>%
group_by(basin, WaterYear) %>%
summarize(nsites = length(unique(site_name)),
littlerange = range(logYield)[2]-range(logYield)[1],
littlesd = sd(logYield),
littlevar = var(logYield)) %>%
ungroup() %>%
left_join(varbig) %>%
mutate(pe_range = ((littlerange-bigrange)/bigrange),
pe_sd = ((littlesd-bigsd)/bigsd),
pe_var = ((littlevar-bigvar)/bigvar)) %>%
left_join(wateravail %>% select(basin, WaterYear, totalyield, totalyield_z, totalyield_sum, totalyield_sum_z, tyz_perc, tyz_sum_perc)) %>%
filter(WaterYear %in% wtryrs) %>%
mutate(wylab = substr(WaterYear, 3, 4)) %>%
arrange(totalyield_sum_z)
# calculate annual median summer flow
annmed <- tempdat %>%
#filter(WaterYear %in% c(lowyr, highyr)) %>%
group_by(site_name, WaterYear) %>%
summarize(medlogYield = median(logYield, na.rm = TRUE)) %>%
ungroup()
# arrange years by total annual yield
wtryrs_arranged <- as.numeric(unlist(pedat %>% select(WaterYear)))
# plot it
plotlist_sn <- list()
for(i in 1:length(wtryrs_arranged)) {
mylittleg <- siteinfo_sp %>% filter(site_name %in% orderr) %>% left_join(annmed %>% filter(WaterYear == wtryrs_arranged[i]))
mylittleg_sheds <- sheds %>% filter(site_name %in% orderr) %>% left_join(annmed %>% filter(WaterYear == wtryrs_arranged[i])) %>% arrange(desc(area_sqmi))
plotlist_sn[[i]] <- local({
i <- i
ggplot() +
geom_sf(data = st_as_sf(mysheds), color = "black", fill = "white", linewidth = 0.4) +
geom_sf(data = mylittleg_sheds, aes(fill = medlogYield), color = "black") +
scale_fill_viridis(option = "G", direction = 1, limits = range(annmed$medlogYield), na.value = "grey") +
geom_sf(data = st_as_sf(mynet), color = "white", linewidth = 1, lineend = "round") +
geom_sf(data = st_as_sf(mynet), color = "royalblue4", linewidth = 0.6, lineend = "round") +
geom_sf(data = mylittleg, shape = 21, fill = "white", size = 2) +
labs(fill = "Median\nsummer\nlog(Yield)") + #annotation_scale() +
coord_sf(xlim = range(st_coordinates(mylittleg_sheds)[,1]), ylim = range(st_coordinates(mylittleg_sheds)[,2])) +
theme_bw() + theme(axis.title.x = element_blank(), axis.title.y = element_blank(), legend.position = "none", axis.text = element_blank()) +
annotate("label", x = -Inf, y = -Inf, label = paste(pedat$WaterYear[i], " (", pedat$tyz_sum_perc[i], "%)", sep = ""), vjust = -0.15, hjust = -0.05, size = 5)})
}
ggarrange(plotlist = plotlist_sn, common.legend = TRUE, legend = "right")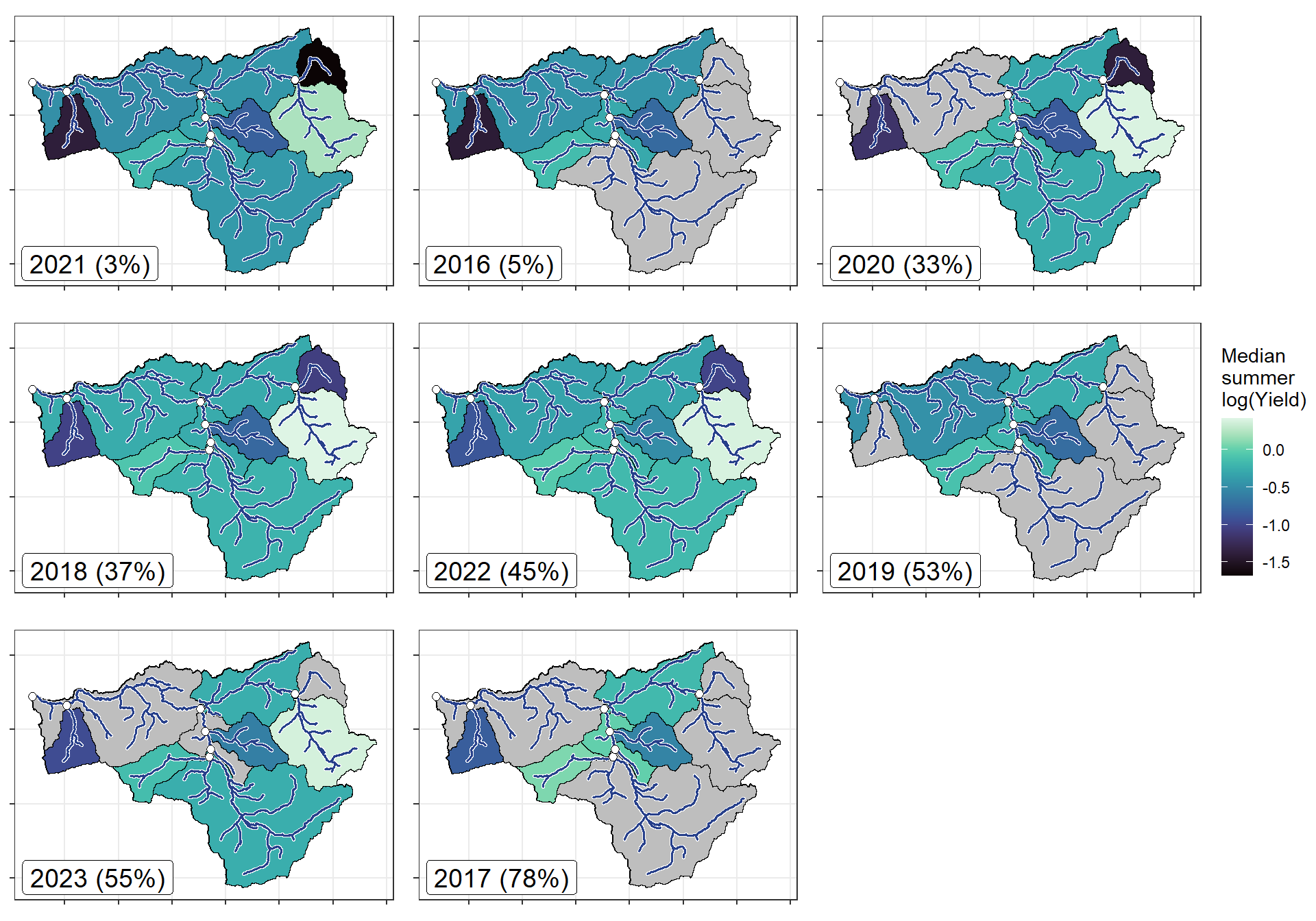
bas <- "Donner Blitzen"
orderr <- c(donnerorder, "Donner Blitzen River nr Frenchglen NWIS")
wtryrs <- c(2016:2024)
mysheds <- vect("C:/Users/jbaldock/OneDrive - DOI/Documents/USGS/EcoDrought/EcoDrought Working/EcoDrought-Analysis/Watershed Delineation/Watersheds/Oreg_Watersheds.shp")
mysheds <- mysheds[mysheds$site_id == "DBF",]
mynet <- vect("C:/Users/jbaldock/OneDrive - DOI/Documents/USGS/EcoDrought/EcoDrought Working/EcoDrought-Analysis/Watershed Delineation/Streams/Oreg_Streams.shp")
crs(mynet) <- crs(mysheds)
mynet <- crop(mynet, mysheds)
# points
mylittleg <- siteinfo_sp %>% filter(site_name %in% orderr) %>% mutate(site_name = factor(site_name, levels = donnerorder))
# edit geometry to reduce overlap
st_geometry(mylittleg)[mylittleg$site_name == "Donner Blitzen ab Fish NWIS"] <- st_point(c(-118.84315, 42.75476))
st_geometry(mylittleg)[mylittleg$site_name == "Fish Creek"] <- st_point(c(-118.83173, 42.75911))
# filter data
tempdat <- dat_clean %>%
filter(basin == bas, !is.na(logYield), Month %in% c(7:9)) %>%
mutate(site_name = factor(site_name, levels = orderr))
nsites <- length(unique(tempdat$site_name))
tempdat_big <- dat_clean_big %>% filter(basin == bas, !is.na(logYield), Month %in% c(7:9), WaterYear %in% unique(tempdat$WaterYear))
# calculate variability for reference gage
varbig <- tempdat_big %>%
group_by(WaterYear) %>%
summarize(bigrange = range(logYield)[2]-range(logYield)[1],
bigsd = sd(logYield),
bigvar = var(logYield)) %>%
ungroup()
# calculate total summer water availability from reference gage
#summerflow <- tempdat_big %>% group_by(WaterYear) %>% summarize(summeryield = sum(Yield_mm), summeryield_log = log(sum(Yield_mm))) %>% ungroup()
#wateravail2 <- wateravail %>% select(basin, WaterYear, totalyield, totalyield_z)
# calculate relative variation
pedat <- tempdat %>%
group_by(basin, WaterYear) %>%
summarize(nsites = length(unique(site_name)),
littlerange = range(logYield)[2]-range(logYield)[1],
littlesd = sd(logYield),
littlevar = var(logYield)) %>%
ungroup() %>%
left_join(varbig) %>%
mutate(pe_range = ((littlerange-bigrange)/bigrange),
pe_sd = ((littlesd-bigsd)/bigsd),
pe_var = ((littlevar-bigvar)/bigvar)) %>%
left_join(wateravail %>% select(basin, WaterYear, totalyield, totalyield_z, totalyield_sum, totalyield_sum_z, tyz_perc, tyz_sum_perc)) %>%
filter(WaterYear %in% wtryrs) %>%
mutate(wylab = substr(WaterYear, 3, 4)) %>%
arrange(totalyield_sum_z)
# calculate annual median summer flow
annmed <- tempdat %>%
group_by(site_name, WaterYear) %>%
summarize(medlogYield = median(logYield, na.rm = TRUE)) %>%
ungroup() %>%
bind_rows(tempdat_big %>%
group_by(site_name, WaterYear) %>%
summarize(medlogYield = median(logYield, na.rm = TRUE)) %>%
ungroup())
# arrange years by total annual yield
wtryrs_arranged <- as.numeric(unlist(pedat %>% select(WaterYear)))
# plot it
plotlist_db <- list()
for(i in 1:length(wtryrs_arranged)) {
mylittleg <- siteinfo_sp %>% filter(site_name %in% orderr) %>% left_join(annmed %>% filter(WaterYear == wtryrs_arranged[i]))
mylittleg_sheds <- sheds %>% filter(site_name %in% orderr) %>% left_join(annmed %>% filter(WaterYear == wtryrs_arranged[i])) %>% arrange(desc(area_sqmi))
plotlist_db[[i]] <- local({
i <- i
ggplot() +
geom_sf(data = st_as_sf(mysheds), color = "black", fill = "white", linewidth = 0.4) +
geom_sf(data = mylittleg_sheds, aes(fill = medlogYield), color = "black") +
scale_fill_viridis(option = "G", direction = 1, limits = range(annmed$medlogYield), na.value = "grey") +
geom_sf(data = st_as_sf(mynet), color = "white", linewidth = 1, lineend = "round") +
geom_sf(data = st_as_sf(mynet), color = "royalblue4", linewidth = 0.6, lineend = "round") +
geom_sf(data = mylittleg, shape = 21, fill = "white", size = 2) +
labs(fill = "Median\nsummer\nlog(Yield)") + #annotation_scale() +
coord_sf(xlim = range(st_coordinates(mylittleg_sheds)[,1]), ylim = range(st_coordinates(mylittleg_sheds)[,2])) +
theme_bw() + theme(axis.title.x = element_blank(), axis.title.y = element_blank(), legend.position = "none", axis.text = element_blank()) +
annotate("label", x = -Inf, y = -Inf, label = paste(pedat$WaterYear[i], " (", pedat$tyz_sum_perc[i], "%)", sep = ""), vjust = -0.15, hjust = -0.05, size = 5)})
}
ggarrange(plotlist = plotlist_db, common.legend = TRUE, legend = "right")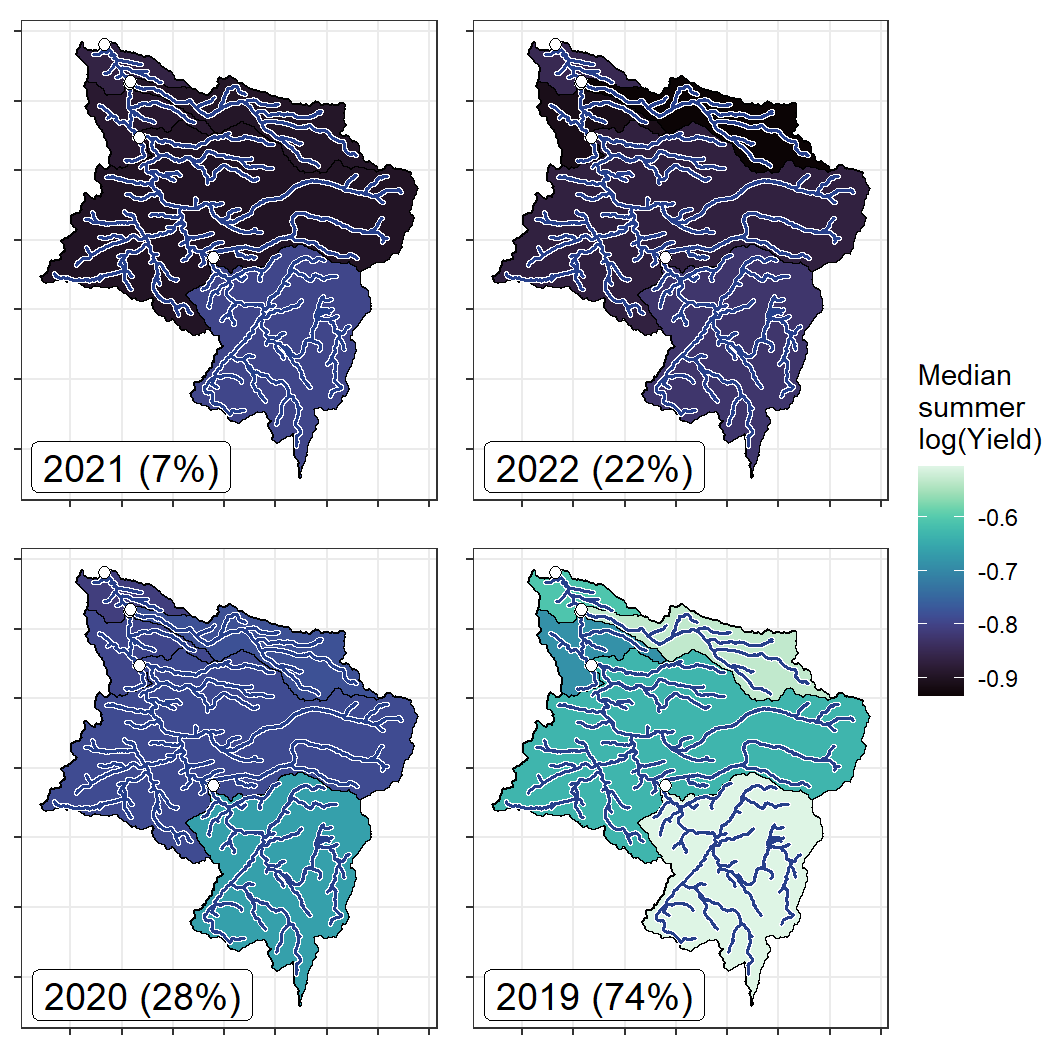
Create function to plot interannual distribution of streamflow values, annual distributions of streamflow values, and scatterplot plot of spatial streamflow heterogeneity by water availability
portfolioplot <- function(bas, orderr, type = c("interann", "annual", "scatter"), wtryrs) {
# filter data
tempdat <- dat_clean %>%
filter(basin == bas, !is.na(logYield), Month %in% c(7:9), WaterYear %in% wtryrs) %>%
mutate(site_name = factor(site_name, levels = orderr))
nsites <- length(unique(tempdat$site_name))
tempdat_big <- dat_clean_big %>% filter(basin == bas, !is.na(logYield), Month %in% c(7:9), WaterYear %in% unique(tempdat$WaterYear))
# calculate variability for reference gage
varbig <- tempdat_big %>%
group_by(WaterYear) %>%
summarize(bigrange = range(logYield)[2]-range(logYield)[1],
bigsd = sd(logYield),
bigvar = var(logYield)) %>%
ungroup()
# calculate total summer water availability from reference gage
#summerflow <- tempdat_big %>% group_by(WaterYear) %>% summarize(summeryield = sum(Yield_mm), summeryield_log = log(sum(Yield_mm))) %>% ungroup()
#wateravail2 <- wateravail %>% select(basin, WaterYear, totalyield, totalyield_z)
# calculate relative variation
pedat <- tempdat %>%
group_by(basin, WaterYear) %>%
summarize(nsites = length(unique(site_name)),
littlerange = range(logYield)[2]-range(logYield)[1],
littlesd = sd(logYield),
littlevar = var(logYield)) %>%
ungroup() %>%
left_join(varbig) %>%
mutate(pe_range = ((littlerange-bigrange)/bigrange)*100,
pe_sd = ((littlesd-bigsd)/bigsd),
pe_var = ((littlevar-bigvar)/bigvar)) %>%
left_join(wateravail %>% select(basin, WaterYear, totalyield, totalyield_z, totalyield_sum, totalyield_sum_z, tyz_sum_perc)) %>%
filter(WaterYear %in% wtryrs) %>%
mutate(wylab = substr(WaterYear, 3, 4))
# interannual
pint <- ggplot() +
geom_density(data = tempdat, aes(x = logYield, y = ..scaled.., color = site_name, fill = site_name), size = 0.8) +
scale_color_manual(values = cet_pal(nsites, name = "i1")) +
scale_fill_manual(values = alpha(cet_pal(nsites, name = "i1"), 0.1)) +
geom_density(data = tempdat_big, aes(x = logYield, y = ..scaled..), color = "grey40", fill = alpha("grey40", 0.2), size = 0.8) +
xlab("Summer log(Yield, mm/day)") + ylab("Scaled density") +
theme_bw() + theme(panel.grid.major = element_blank(), panel.grid.minor = element_blank(),
axis.text = element_text(color = "black"), legend.position = "none")
# annual
pann <- ggplot() +
geom_density(data = tempdat, aes(x = logYield, y = ..scaled.., color = site_name, fill = site_name), size = 0.8) +
scale_color_manual(values = cet_pal(nsites, name = "i1")) +
scale_fill_manual(values = alpha(cet_pal(nsites, name = "i1"), 0.1)) +
geom_density(data = tempdat_big, aes(x = logYield, y = ..scaled..), color = "grey40", fill = alpha("grey40", 0.2), size = 0.8) +
xlab("Summer log(Yield, mm/day)") + ylab("Scaled density") +
theme_bw() + theme(panel.grid.major = element_blank(), panel.grid.minor = element_blank(),
axis.text = element_text(color = "black"), legend.position = "none") +
facet_wrap(~factor(WaterYear, levels = as.numeric(unlist(pedat %>% arrange(totalyield_sum_z) %>% select(WaterYear)))))
# portfolio effect by water availability
ppew <- pedat %>%
ggplot(aes(x = tyz_sum_perc, y = pe_range, label = wylab)) +
geom_abline(slope = 0, intercept = 0, linetype = 2) +
geom_smooth(method = "lm", color = "black") +
geom_point(shape = 21, fill = "skyblue1", size = 3) +
geom_text(vjust = -0.7, color = "grey40") +
xlab("Water availability") + ylab("Relative difference in range") +
theme_bw() + theme(panel.grid.major = element_blank(), panel.grid.minor = element_blank(), axis.text = element_text(color = "black")) +
guides(color = guide_legend(title="Water year")) + xlim(0,100) + ylim(-100,450)
if(type == "interannual") { return(pint) }
if(type == "annual") { return(pann) }
if(type == "scatter") { return(ppew) }
if(type == "table") { return(pedat) }
}Generate plots
denwb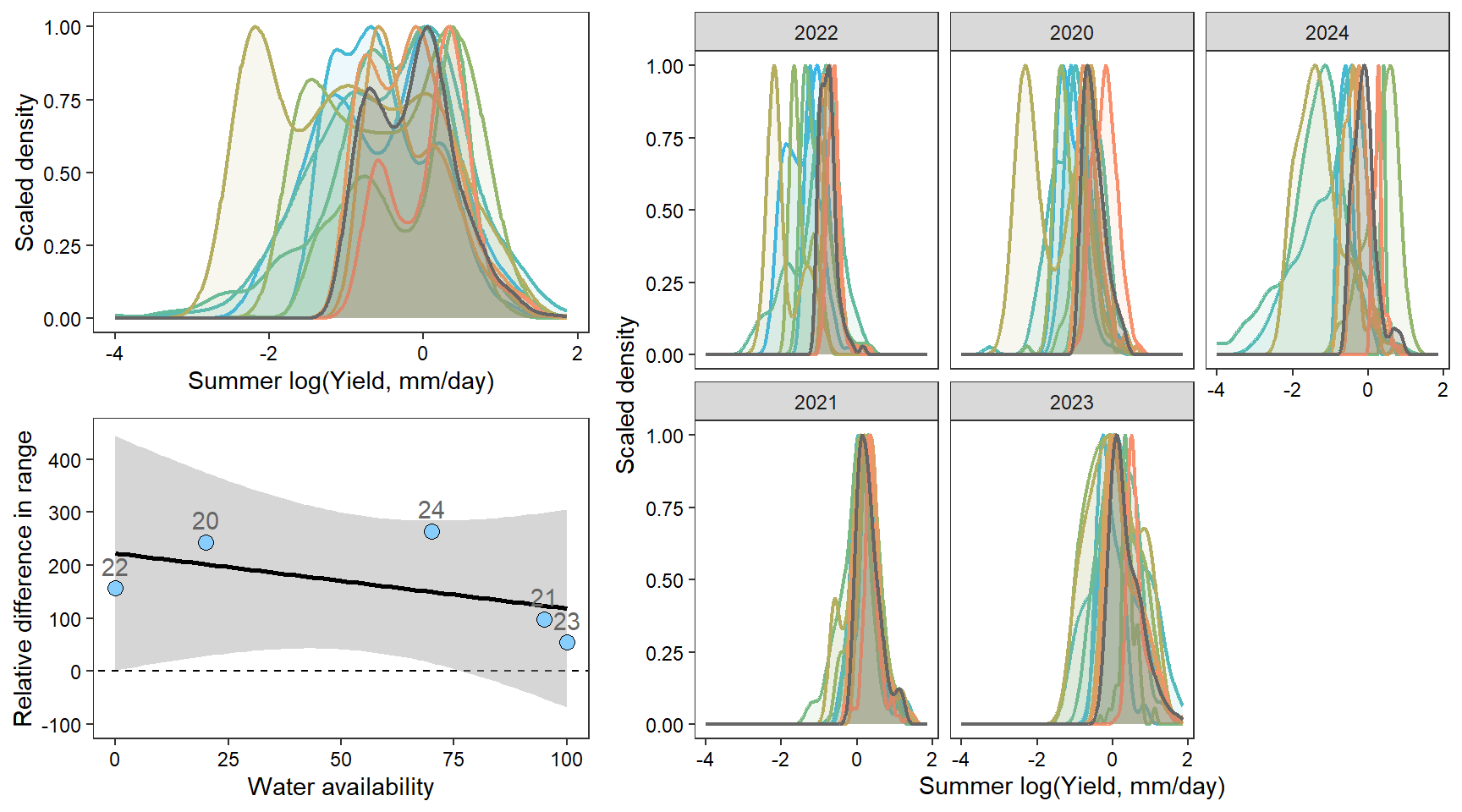
denpa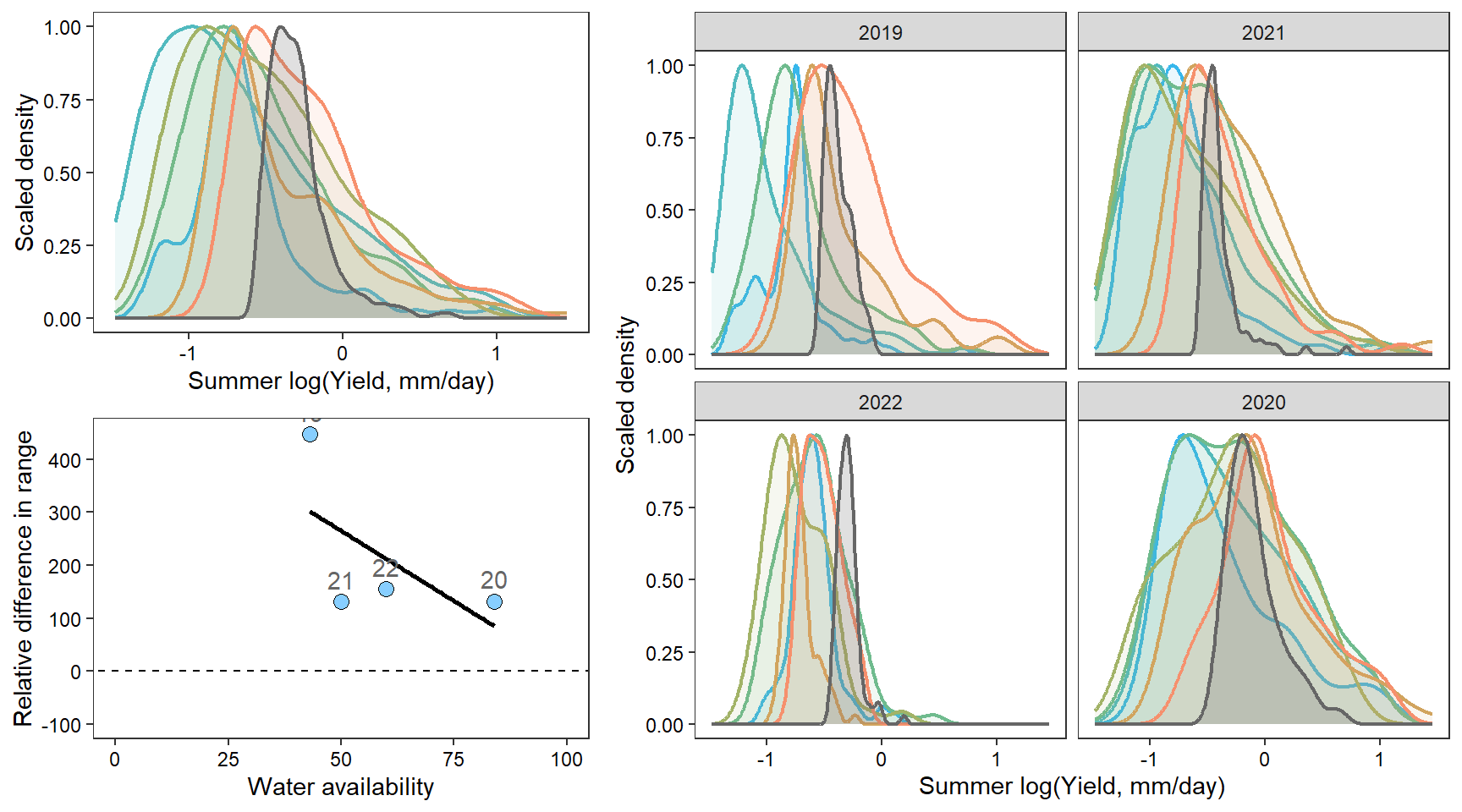
denst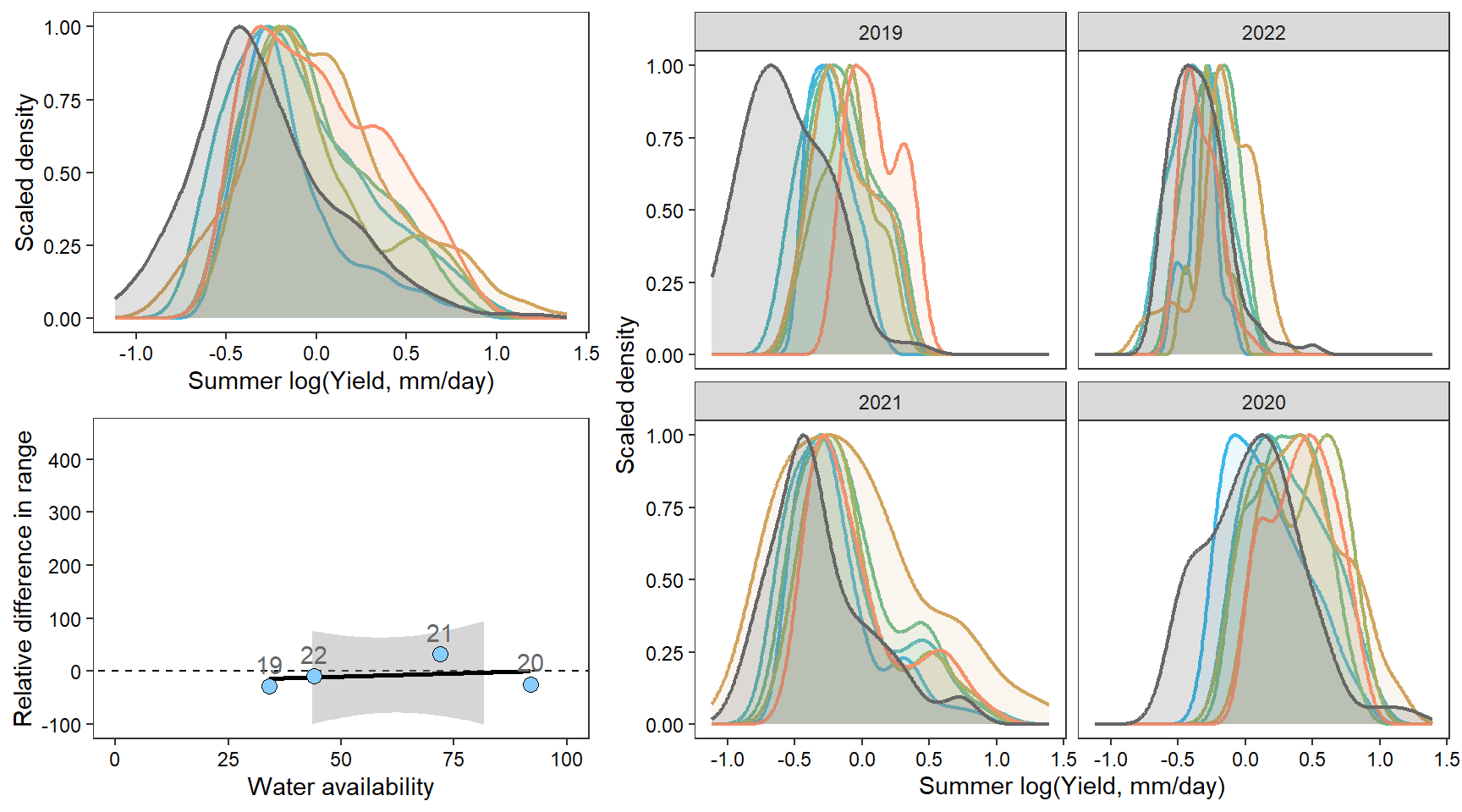
denfl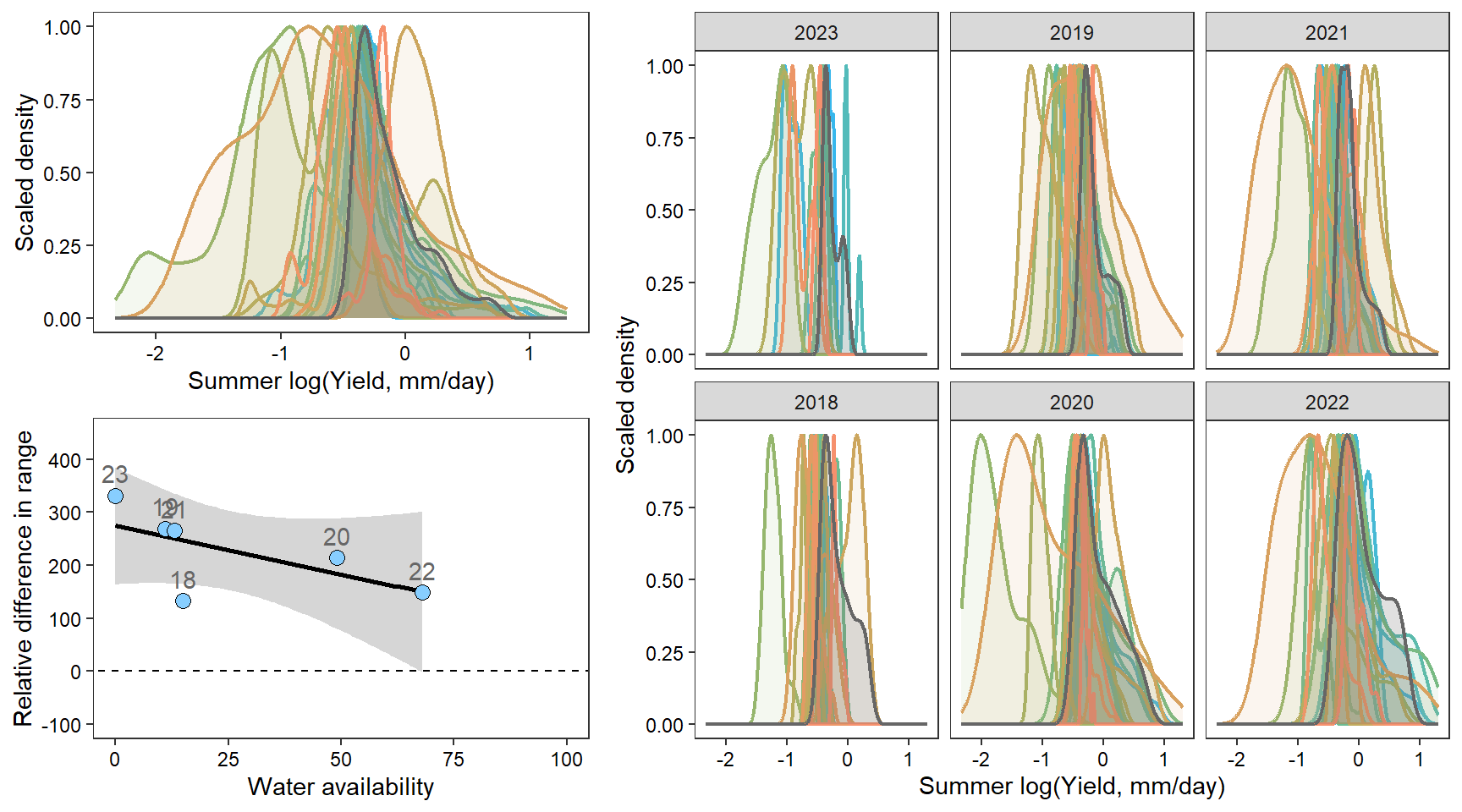
denye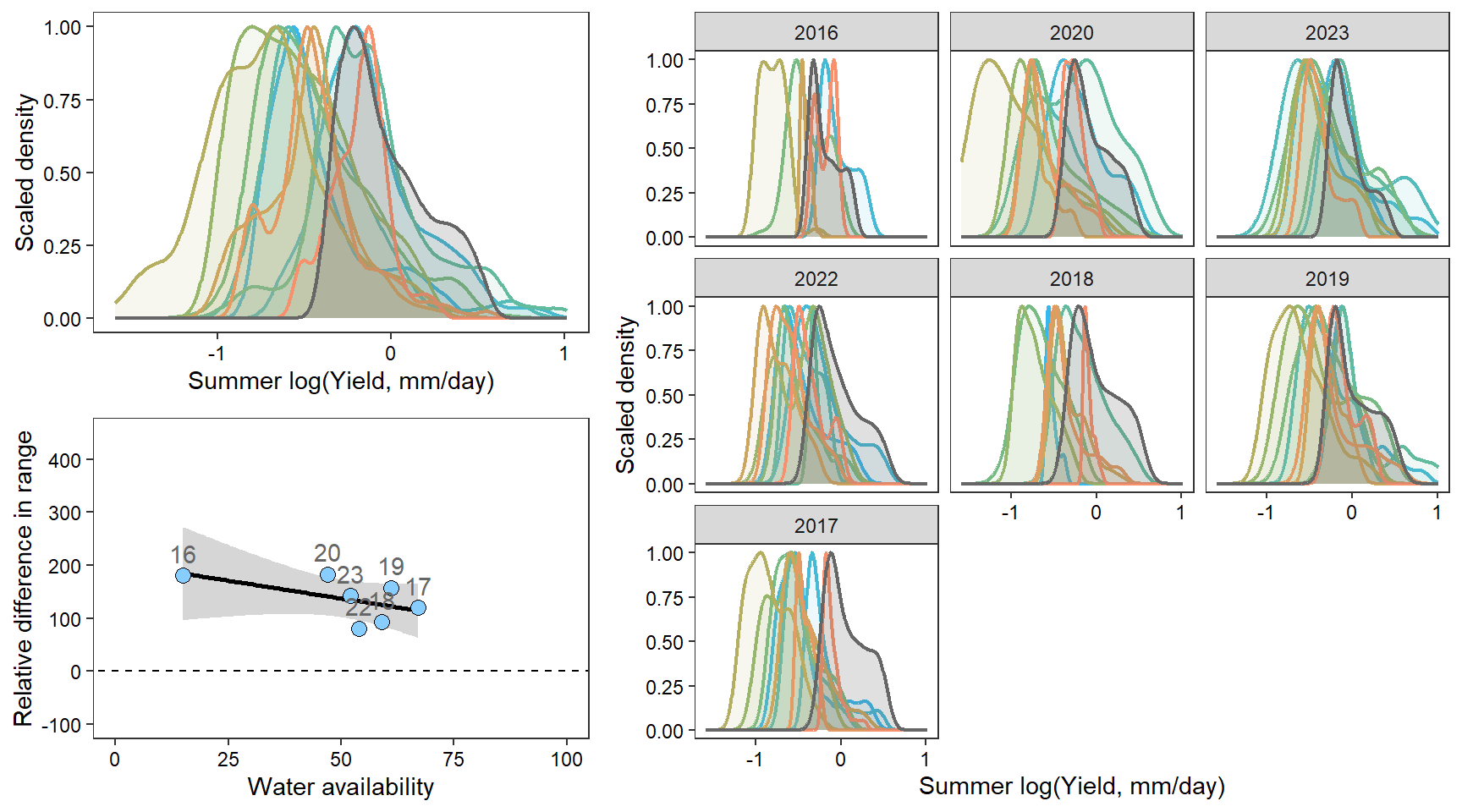
densn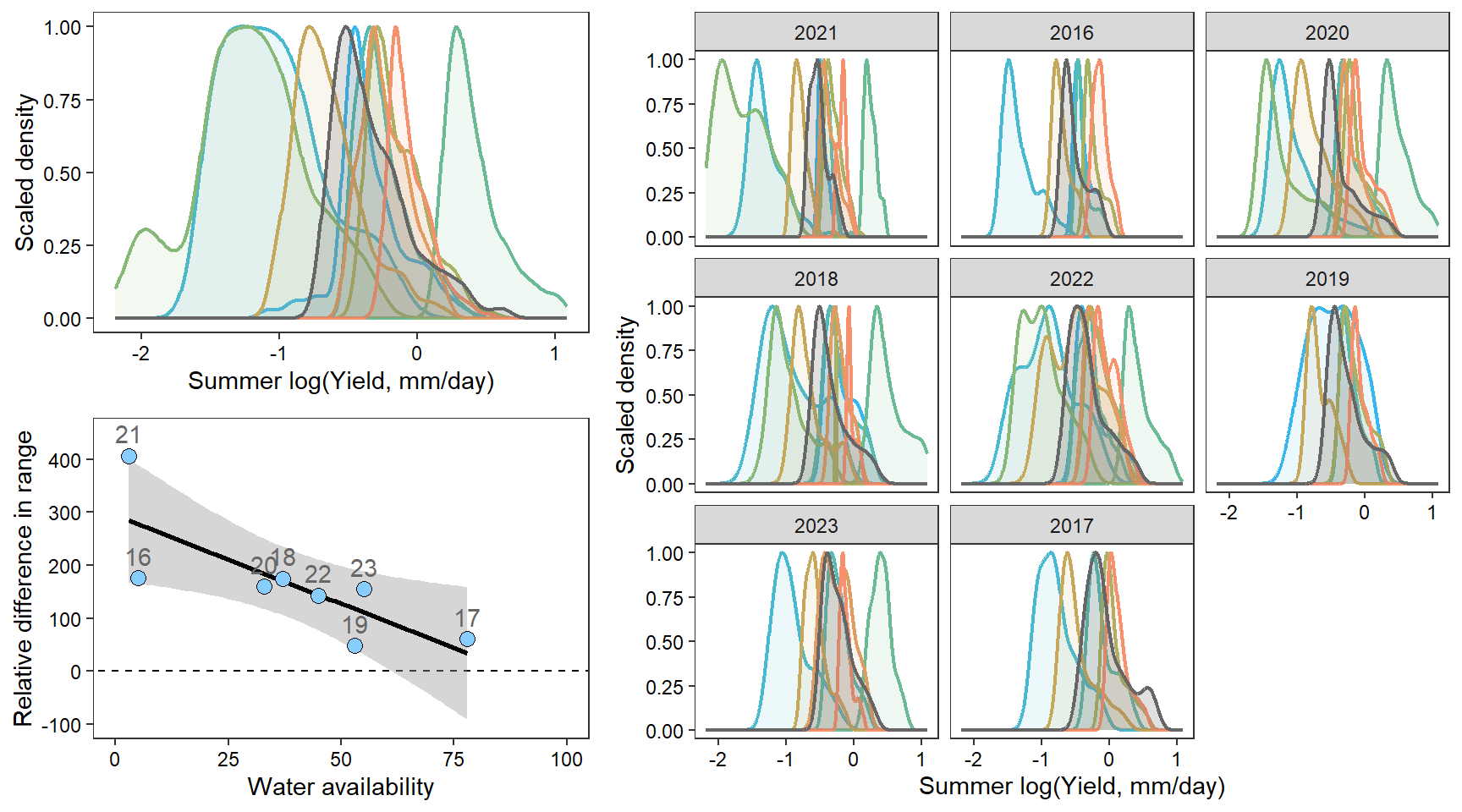
dendb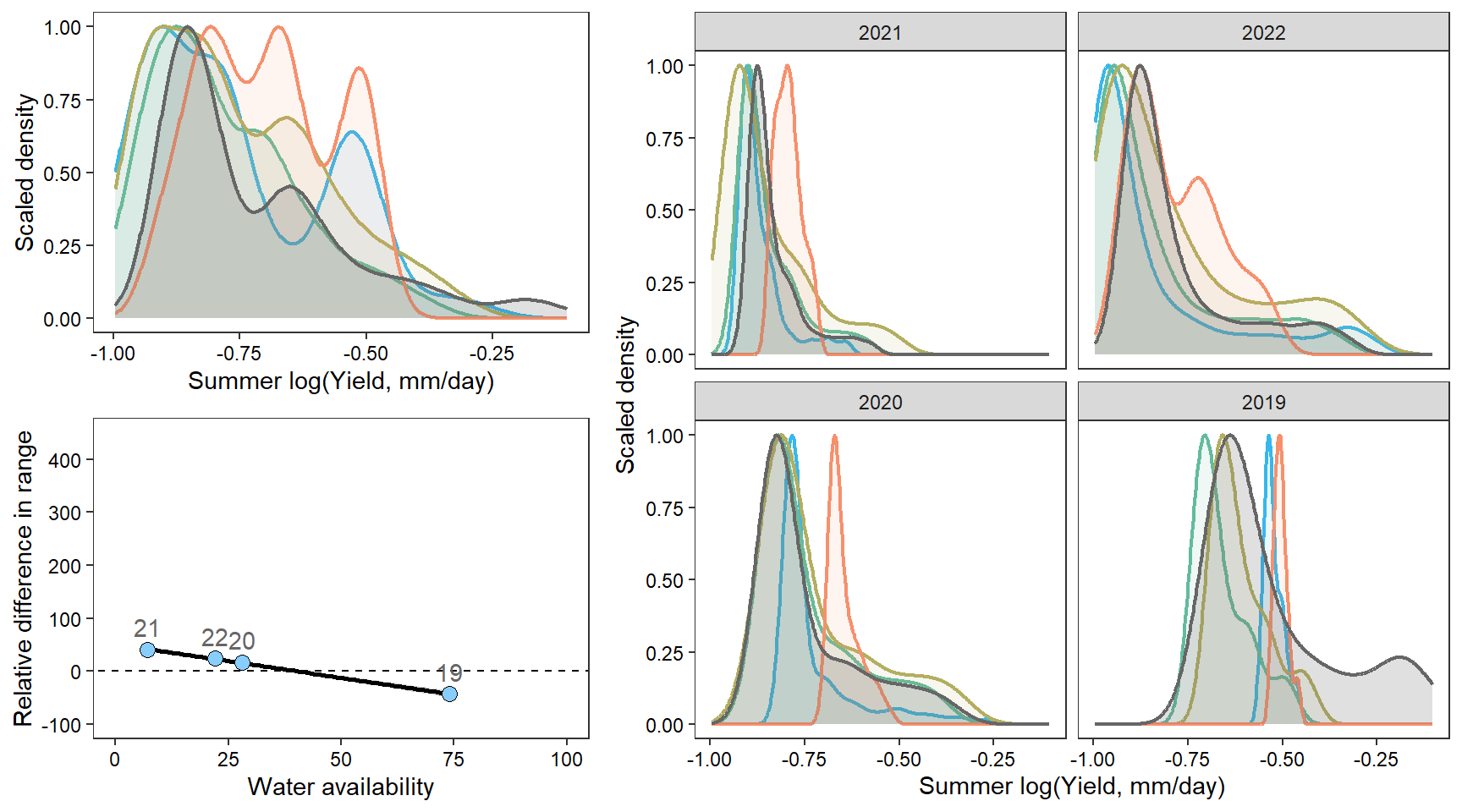
How does regional water availability affect spatial streamflow heterogeneity (relative difference range of streamflow values, headwaters vs. reference gages)?
Set color palette
mycols <- brewer.pal(7, "Set2")FLOW REGIME: Relative difference in the range of summer flow values across all little g’s compared to range of flow values at big G.
Some data manipulation
# define basin-years to keep
keepyears <- bind_rows(
tibble(basin = "West Brook", WaterYear = c(2020:2024)),
tibble(basin = "Paine Run", WaterYear = c(2019:2022)),
tibble(basin = "Staunton River", WaterYear = c(2019:2022)),
tibble(basin = "Flathead", WaterYear = c(2018:2024)),
tibble(basin = "Shields River", WaterYear = c(2016:2020,2022:2024)),
tibble(basin = "Snake River", WaterYear = c(2016:2024)),
tibble(basin = "Donner Blitzen", WaterYear = c(2016:2024)),
) %>% mutate(keep = "yes")
# calculate relative difference in range as above
mydat <- dat_clean %>%
filter(Month %in% c(7:9)) %>%
group_by(basin, WaterYear) %>%
summarize(nsites = length(unique(site_name)),
littlerange = range(logYield)[2]-range(logYield)[1]) %>%
ungroup() %>%
left_join(dat_clean_big %>%
filter(Month %in% c(7:9)) %>%
group_by(basin, WaterYear) %>%
summarize(bigrange = range(logYield)[2]-range(logYield)[1]) %>%
ungroup()) %>%
mutate(pe_range = ((littlerange-bigrange)/bigrange)*100) %>%
left_join(wateravail %>% select(basin, WaterYear, totalyield:tyz_sum_perc)) %>%
left_join(keepyears) %>% filter(keep == "yes") %>%
mutate(basin = ifelse(basin == "Shields River", "Yellowstone River",
ifelse(basin == "Flathead", "Flathead River",
ifelse(basin == "Donner Blitzen", "Donner-Blitzen River", basin)))) %>%
mutate(basin = factor(basin, levels = c("West Brook", "Staunton River", "Paine Run",
"Flathead River", "Yellowstone River", "Snake River", "Donner-Blitzen River")))
mydat# A tibble: 38 × 14
basin WaterYear nsites littlerange bigrange pe_range site_name totalyield
<fct> <dbl> <int> <dbl> <dbl> <dbl> <chr> <dbl>
1 Donner-B… 2019 4 0.332 0.583 -43.1 Donner B… 278.
2 Donner-B… 2020 4 0.605 0.516 17.3 Donner B… 152.
3 Donner-B… 2021 4 0.474 0.336 41.1 Donner B… 122.
4 Donner-B… 2022 4 0.741 0.597 24.0 Donner B… 125.
5 Flathead… 2018 18 1.82 0.783 133. North Fo… 654.
6 Flathead… 2019 19 2.47 0.668 269. North Fo… 448.
7 Flathead… 2020 19 3.49 1.11 214. North Fo… 605.
8 Flathead… 2021 17 2.76 0.756 265. North Fo… 483.
9 Flathead… 2022 16 2.76 1.11 149. North Fo… 793.
10 Flathead… 2023 9 1.94 0.451 331. North Fo… 372.
# ℹ 28 more rows
# ℹ 6 more variables: totalyield_z <dbl>, totalyield_sum <dbl>,
# totalyield_sum_z <dbl>, tyz_perc <dbl>, tyz_sum_perc <dbl>, keep <chr>Show simple linear model summary, weighted by number of sites
summary(lm(pe_range ~ tyz_sum_perc, data = mydat, weights = nsites))
Call:
lm(formula = pe_range ~ tyz_sum_perc, data = mydat, weights = nsites)
Weighted Residuals:
Min 1Q Median 3Q Max
-503.62 -205.22 -25.09 108.84 639.45
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 239.1231 26.7291 8.946 1.12e-10 ***
tyz_sum_perc -1.8174 0.5199 -3.496 0.00127 **
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 262.6 on 36 degrees of freedom
Multiple R-squared: 0.2534, Adjusted R-squared: 0.2327
F-statistic: 12.22 on 1 and 36 DF, p-value: 0.001273Show distribution of spatial streamflow heterogeneity by basin. Lots of structuring by basin, driven in large part by Staunton and Donner-Blitzen Rivers.
par(mar = c(9,4,0.5,0.5))
boxplot(pe_range ~ basin, data = mydat, ylab = "Spatial streamflow heterogeneity", xlab = "", las = 2, col = mycols)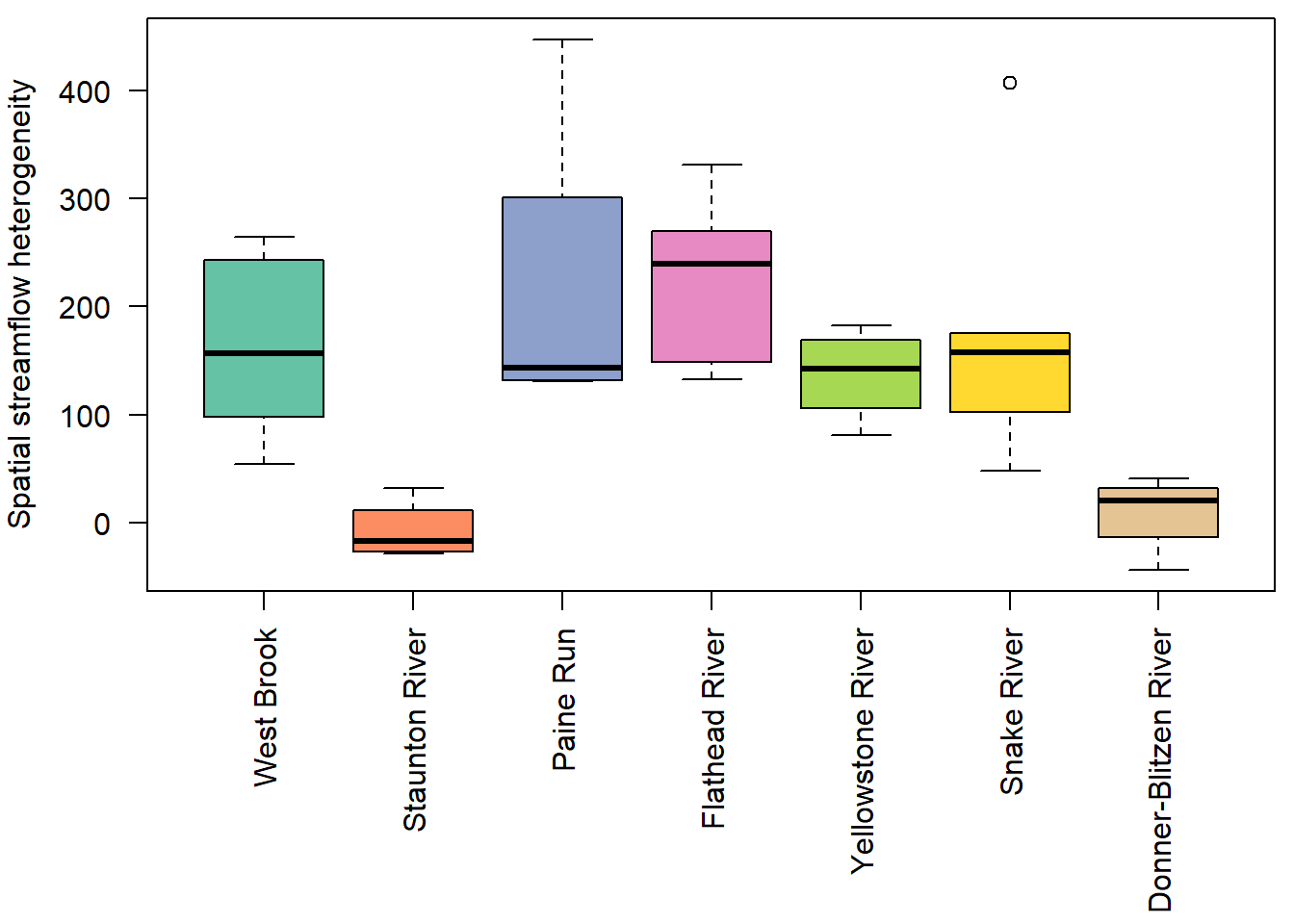
Use a random slope/random intercept mixed effects model to estimate the among-basin mean effect of regional water availability on spatial streamflow heterogeneity.
Notes:
mydat <- mydat %>% mutate(z_tyz_sum_perc = scale(tyz_sum_perc))
lmod <- lmer(pe_range ~ z_tyz_sum_perc + (1 + z_tyz_sum_perc | basin), data = mydat)
summary(lmod)Linear mixed model fit by REML. t-tests use Satterthwaite's method [
lmerModLmerTest]
Formula: pe_range ~ z_tyz_sum_perc + (1 + z_tyz_sum_perc | basin)
Data: mydat
REML criterion at convergence: 430.4
Scaled residuals:
Min 1Q Median 3Q Max
-1.5512 -0.4206 -0.1253 0.2584 2.8102
Random effects:
Groups Name Variance Std.Dev. Corr
basin (Intercept) 7810.1 88.37
z_tyz_sum_perc 609.8 24.69 -0.92
Residual 5127.9 71.61
Number of obs: 38, groups: basin, 7
Fixed effects:
Estimate Std. Error df t value Pr(>|t|)
(Intercept) 133.13 35.60 5.51 3.740 0.0113 *
z_tyz_sum_perc -45.39 16.29 3.62 -2.787 0.0554 .
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Correlation of Fixed Effects:
(Intr)
z_tyz_sm_pr -0.521Get p-values for global slope and intercept: (doesn’t to run in Quarto…works fine in R)
coef(summary(as_lmerModLmerTest(lmod))) Estimate Std. Error df t value Pr(>|t|)
(Intercept) 133.13376 35.60169 5.510014 3.739534 0.01125212
z_tyz_sum_perc -45.39251 16.28830 3.620345 -2.786817 0.05538425Plot relationship between spatial streamflow heterogeneity and regional water availability with global (among-population mean) regression line.
# get predicted values and 95% credible interval
effects_tyz <- effects::effect(term = "z_tyz_sum_perc", mod = as_lmerModLmerTest(lmod), xlevels = list(z_tyz_sum_perc = seq(min(mydat$z_tyz_sum_perc), max(mydat$z_tyz_sum_perc), length.out = 1000)), se = list(level = 0.95))
x_tyz <- as_tibble(effects_tyz) %>% mutate(tyz_sum_perc = (z_tyz_sum_perc * attr(mydat$z_tyz_sum_perc, "scaled:scale")) + attr(mydat$z_tyz_sum_perc, "scaled:center"))
# trim data for panel labesl
mydat_labs <- bind_rows(mydat %>% filter(basin == "West Brook", WaterYear %in% c(2020,2021)),
mydat %>% filter(basin == "Snake River", WaterYear %in% c(2021,2022))) %>%
mutate(labs = c("b", "c", "d", "e"))
# plot
randiffplot <- ggplot() +
geom_ribbon(data = x_tyz, aes(x = tyz_sum_perc, ymin = lower, ymax = upper), fill = "grey80") +
geom_line(data = x_tyz, aes(x = tyz_sum_perc, y = fit), color = "black", size = 1.25, lineend = "round") +
geom_point(data = mydat, aes(x = tyz_sum_perc, y = pe_range, fill = basin, size = nsites), shape = 21) +
scale_fill_brewer(palette = "Set2") +
geom_text(data = mydat_labs, aes(x = tyz_sum_perc, y = pe_range, label = labs), size = 3) +
theme_bw() + theme(panel.grid = element_blank(), axis.text = element_text(color = "black")) +
ylab("Spatial streamflow heterogeneity (percent difference)") + xlab("Water availability (percentile)") +
guides(fill = guide_legend(title = "Basin", override.aes = list(size = 5), order = 1), size = guide_legend(title = "Number of sites", order = 2)) +
geom_abline(intercept = 0, slope = 0, linetype = "dashed") +
annotate("text", x = Inf, y = Inf, hjust = 1.1, vjust = 1.1, fontface = "italic",
label = paste("p = ", round(coef(summary(as_lmerModLmerTest(lmod)))[2,5], digits = 3)))
randiffplot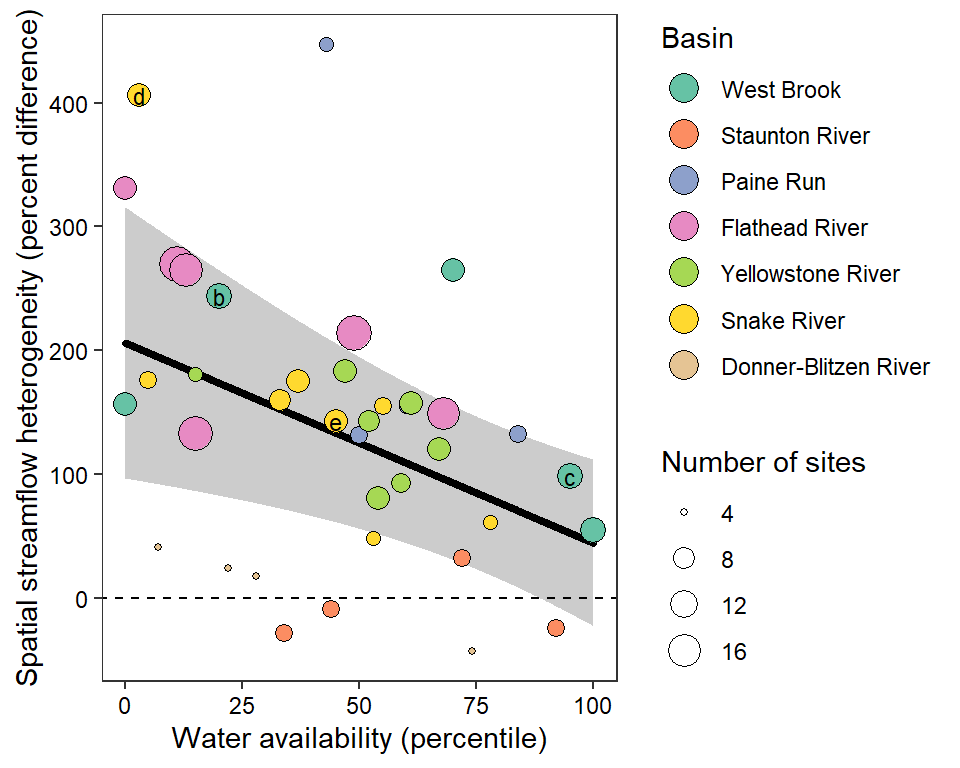
randiffplot1 <- randiffplot
# write to file
# jpeg("C:/Users/jbaldock/OneDrive - DOI/Documents/USGS/EcoDrought/EcoDrought Working/Presentation figs/EcoD_RangeDiff_allsites2.jpg", width = 4.75, height = 5, units = "in", res = 1000)
# randiffplot
# dev.off()Use rptR to decompose variance in spatial streamflow heterogeneity into fixed (regional water availability) and random (basin) effect sources:
rmod <- rptGaussian(pe_range ~ z_tyz_sum_perc + (1 + z_tyz_sum_perc | basin), data = mydat, grname = c("basin", "Fixed"), ratio = TRUE, adjusted = FALSE, nboot = 1000)Bootstrap Progress:print(rmod)
Repeatability estimation using the lmm method
Repeatability for basin
R = 0.539
SE = 0.177
CI = [0.105, 0.791]
P = 0.00764 [LRT]
NA [Permutation]
Repeatability for Fixed
R = 0.132
SE = 0.105
CI = [0.013, 0.403]
P = NA [LRT]
NA [Permutation]rmod$modLinear mixed model fit by REML ['lmerMod']
Formula: pe_range ~ z_tyz_sum_perc + (1 + z_tyz_sum_perc | basin)
Data: data
REML criterion at convergence: 430.4229
Random effects:
Groups Name Std.Dev. Corr
basin (Intercept) 88.37
z_tyz_sum_perc 24.69 -0.92
Residual 71.61
Number of obs: 38, groups: basin, 7
Fixed Effects:
(Intercept) z_tyz_sum_perc
133.13 -45.39 plot(rmod, grname = "basin")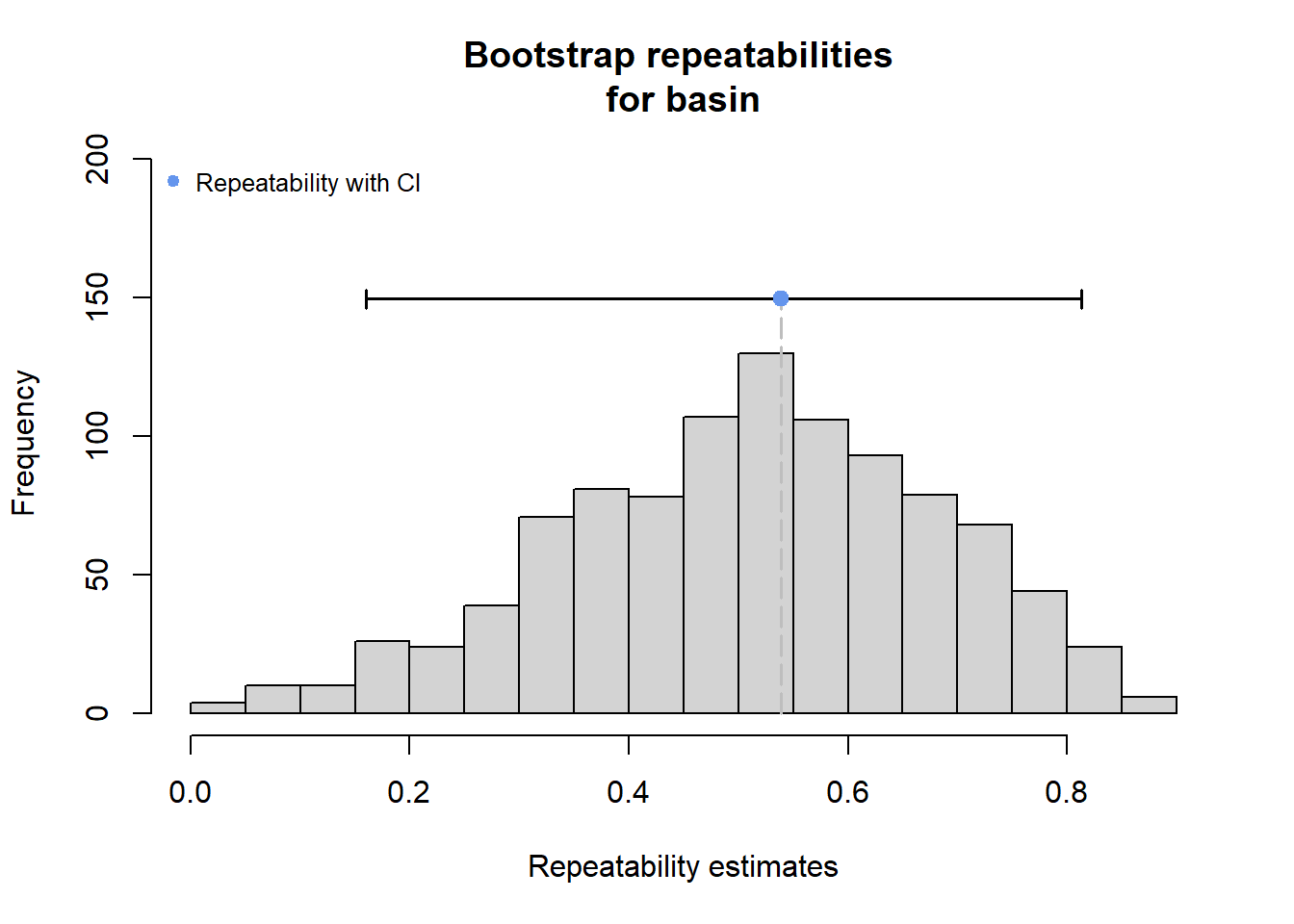
plot(rmod, grname = "Fixed")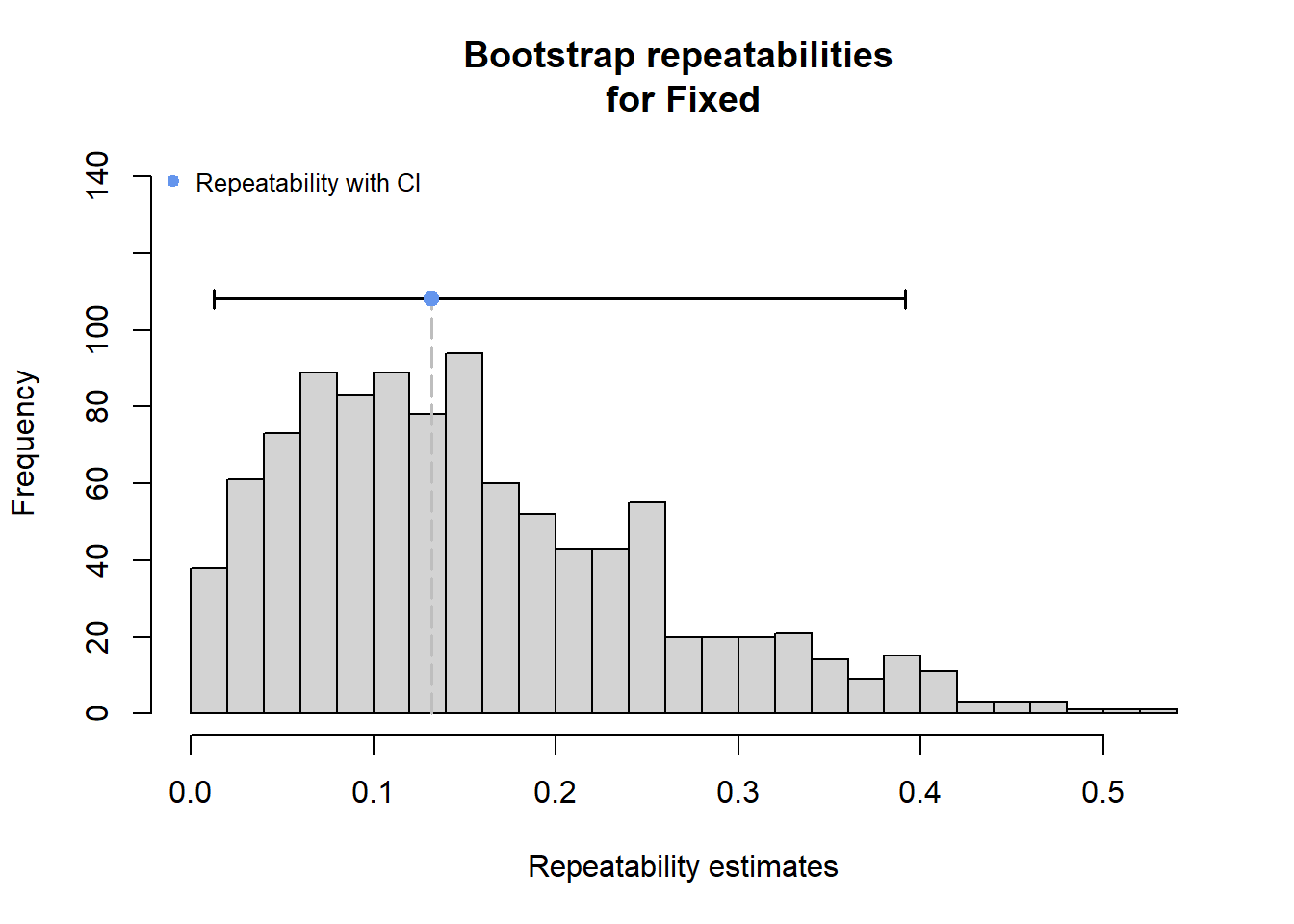
The strong effect of basin is largely driven by Staunton and Donner-Blitzen Rivers. Without those basins, random effect variance shrinks and fixed effect variance expands considerably. Much of this pattern is likely due to low sample sizes (few headwater gages in these basins, particularly in the Donner-Blitzen)
rmod <- rptGaussian(pe_range ~ z_tyz_sum_perc + (1 + z_tyz_sum_perc | basin), data = mydat %>% filter(!basin %in% c("Staunton River", "Donner-Blitzen River")), grname = c("basin", "Fixed"), ratio = TRUE, adjusted = FALSE, nboot = 1000)Bootstrap Progress:print(rmod)
Repeatability estimation using the lmm method
Repeatability for basin
R = 0.037
SE = 0.118
CI = [0, 0.424]
P = 1 [LRT]
NA [Permutation]
Repeatability for Fixed
R = 0.304
SE = 0.128
CI = [0.07, 0.553]
P = NA [LRT]
NA [Permutation]How sensitive are these results to the choice of data (log) transformation, per comments from John Hammond during USGS internal review?
Summary: While the among-network mean effect of water availability on heterogeneity was less significant using un-logged discharge data (p > 0.05), this appeared to be driven by the highly non-normal distribution of raw discharge values, as the reviewer indicated. Importantly, the magnitude of the effect is similar and the qualitative results are unchanged (negative slope).
Data manipulation: use un-logged/raw Yield data to calculation spatial heterogeneity, also use CV rather than ranges
mydat2 <- dat_clean %>%
filter(Month %in% c(7:9)) %>%
group_by(basin, WaterYear) %>%
summarize(nsites = length(unique(site_name)),
littlerange = range(Yield_mm)[2]-range(Yield_mm)[1],
littlecv = sd(Yield_mm)/mean(Yield_mm)) %>%
ungroup() %>%
left_join(dat_clean_big %>%
filter(Month %in% c(7:9)) %>%
group_by(basin, WaterYear) %>%
summarize(bigrange = range(Yield_mm)[2]-range(Yield_mm)[1],
bigcv = sd(Yield_mm)/mean(Yield_mm)) %>%
ungroup()) %>%
mutate(pe_range = ((littlerange-bigrange)/bigrange)*100,
pe_cv = ((littlecv-bigcv)/bigcv)*100) %>%
left_join(wateravail %>% select(basin, WaterYear, totalyield:tyz_sum_perc)) %>%
left_join(keepyears) %>% filter(keep == "yes") %>%
mutate(basin = ifelse(basin == "Shields River", "Yellowstone River",
ifelse(basin == "Flathead", "Flathead River",
ifelse(basin == "Donner Blitzen", "Donner-Blitzen River", basin)))) %>%
mutate(basin = factor(basin, levels = c("West Brook", "Staunton River", "Paine Run",
"Flathead River", "Yellowstone River", "Snake River", "Donner-Blitzen River"))) Fit the mixed effects model
mydat2 <- mydat2 %>% mutate(z_tyz_sum_perc = scale(tyz_sum_perc))
lmod <- lmer(pe_range ~ z_tyz_sum_perc + (1 + z_tyz_sum_perc | basin), data = mydat2)
summary(lmod)Linear mixed model fit by REML. t-tests use Satterthwaite's method [
lmerModLmerTest]
Formula: pe_range ~ z_tyz_sum_perc + (1 + z_tyz_sum_perc | basin)
Data: mydat2
REML criterion at convergence: 523.5
Scaled residuals:
Min 1Q Median 3Q Max
-1.8092 -0.4147 -0.1069 0.3663 3.7590
Random effects:
Groups Name Variance Std.Dev. Corr
basin (Intercept) 79567 282.1
z_tyz_sum_perc 19495 139.6 -1.00
Residual 70913 266.3
Number of obs: 38, groups: basin, 7
Fixed effects:
Estimate Std. Error df t value Pr(>|t|)
(Intercept) 238.131 116.273 4.215 2.048 0.106
z_tyz_sum_perc -86.826 72.670 2.761 -1.195 0.325
Correlation of Fixed Effects:
(Intr)
z_tyz_sm_pr -0.703
optimizer (nloptwrap) convergence code: 0 (OK)
boundary (singular) fit: see help('isSingular')Plot
# get predicted values and 95% credible interval
effects_tyz <- effects::effect(term = "z_tyz_sum_perc", mod = as_lmerModLmerTest(lmod), xlevels = list(z_tyz_sum_perc = seq(min(mydat2$z_tyz_sum_perc), max(mydat2$z_tyz_sum_perc), length.out = 1000)), se = list(level = 0.95))
x_tyz <- as_tibble(effects_tyz) %>% mutate(tyz_sum_perc = (z_tyz_sum_perc * attr(mydat2$z_tyz_sum_perc, "scaled:scale")) + attr(mydat2$z_tyz_sum_perc, "scaled:center"))
# trim data for panel labesl
mydat_labs <- bind_rows(mydat2 %>% filter(basin == "West Brook", WaterYear %in% c(2020,2021)),
mydat2 %>% filter(basin == "Snake River", WaterYear %in% c(2021,2022))) %>%
mutate(labs = c("b", "c", "d", "e"))
# plot
ggplot() +
geom_ribbon(data = x_tyz, aes(x = tyz_sum_perc, ymin = lower, ymax = upper), fill = "grey80") +
geom_line(data = x_tyz, aes(x = tyz_sum_perc, y = fit), color = "black", size = 1.25, lineend = "round") +
geom_point(data = mydat2, aes(x = tyz_sum_perc, y = pe_range, fill = basin, size = nsites), shape = 21) +
scale_fill_brewer(palette = "Set2") +
theme_bw() + theme(panel.grid = element_blank(), axis.text = element_text(color = "black")) +
ylab("Spatial streamflow heterogeneity (percent difference)") + xlab("Water availability (percentile)") +
guides(fill = guide_legend(title = "Basin", override.aes = list(size = 5), order = 1), size = guide_legend(title = "Number of sites", order = 2)) +
geom_abline(intercept = 0, slope = 0, linetype = "dashed")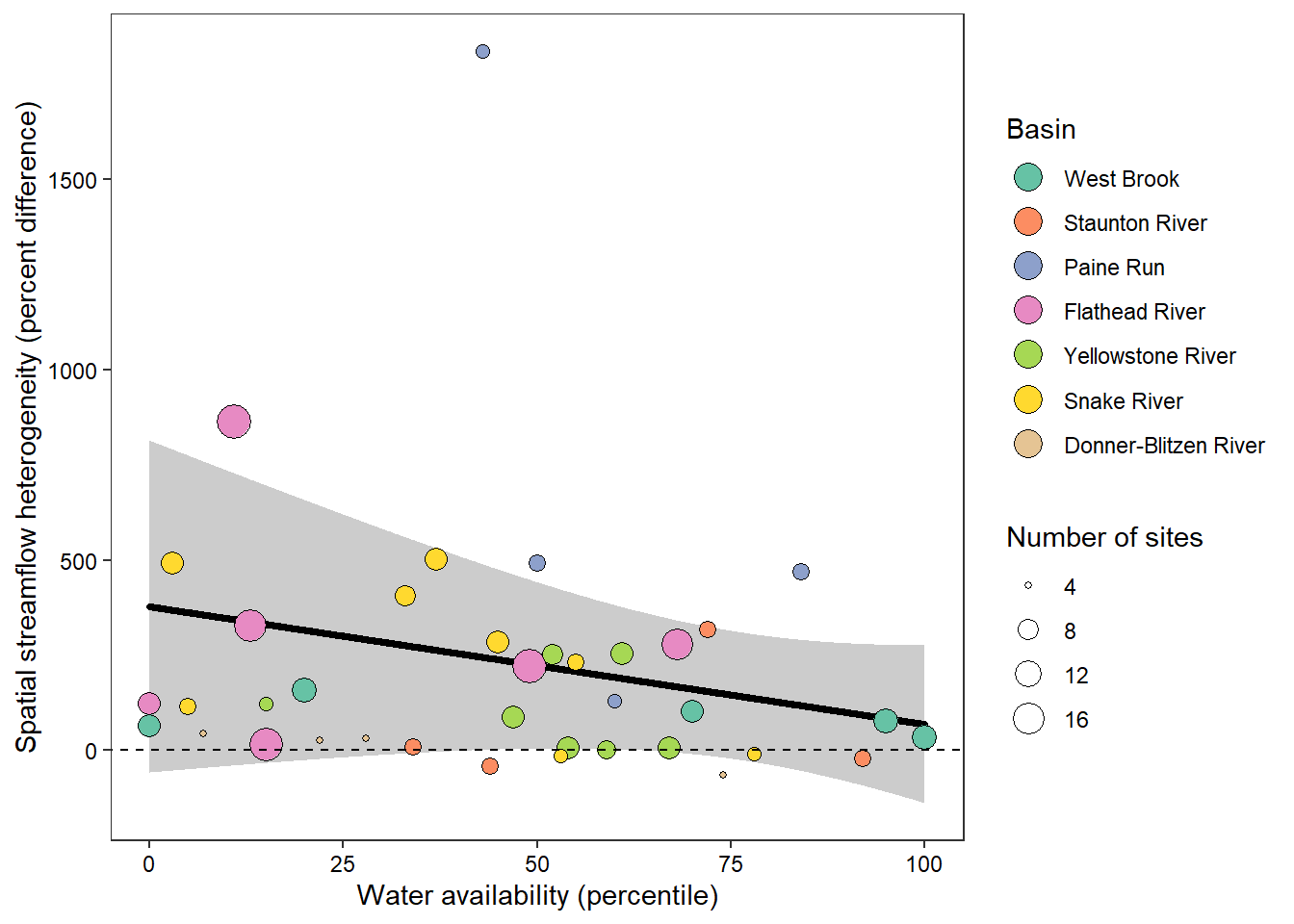
Relative difference in the CV of summer flow values across all little g’s compared to CV of flow values at big G
Fig the mmixed effects model
mydat2 <- mydat2 %>% mutate(z_tyz_sum_perc = scale(tyz_sum_perc))
lmod <- lmer(pe_cv ~ z_tyz_sum_perc + (1 + z_tyz_sum_perc | basin), data = mydat2)
summary(lmod)Linear mixed model fit by REML. t-tests use Satterthwaite's method [
lmerModLmerTest]
Formula: pe_cv ~ z_tyz_sum_perc + (1 + z_tyz_sum_perc | basin)
Data: mydat2
REML criterion at convergence: 450.7
Scaled residuals:
Min 1Q Median 3Q Max
-2.4210 -0.3359 0.0006 0.2983 3.9794
Random effects:
Groups Name Variance Std.Dev. Corr
basin (Intercept) 24752 157.33
z_tyz_sum_perc 8948 94.59 -1.00
Residual 7991 89.39
Number of obs: 38, groups: basin, 7
Fixed effects:
Estimate Std. Error df t value Pr(>|t|)
(Intercept) 88.405 61.551 5.248 1.436 0.208
z_tyz_sum_perc -55.189 39.739 3.675 -1.389 0.243
Correlation of Fixed Effects:
(Intr)
z_tyz_sm_pr -0.889
optimizer (nloptwrap) convergence code: 0 (OK)
boundary (singular) fit: see help('isSingular')Plot
# get predicted values and 95% credible interval
effects_tyz <- effects::effect(term = "z_tyz_sum_perc", mod = as_lmerModLmerTest(lmod), xlevels = list(z_tyz_sum_perc = seq(min(mydat2$z_tyz_sum_perc), max(mydat2$z_tyz_sum_perc), length.out = 1000)), se = list(level = 0.95))
x_tyz <- as_tibble(effects_tyz) %>% mutate(tyz_sum_perc = (z_tyz_sum_perc * attr(mydat2$z_tyz_sum_perc, "scaled:scale")) + attr(mydat2$z_tyz_sum_perc, "scaled:center"))
# trim data for panel labesl
mydat_labs <- bind_rows(mydat2 %>% filter(basin == "West Brook", WaterYear %in% c(2020,2021)),
mydat2 %>% filter(basin == "Snake River", WaterYear %in% c(2021,2022))) %>%
mutate(labs = c("b", "c", "d", "e"))
# plot
ggplot() +
geom_ribbon(data = x_tyz, aes(x = tyz_sum_perc, ymin = lower, ymax = upper), fill = "grey80") +
geom_line(data = x_tyz, aes(x = tyz_sum_perc, y = fit), color = "black", size = 1.25, lineend = "round") +
geom_point(data = mydat2, aes(x = tyz_sum_perc, y = pe_cv, fill = basin, size = nsites), shape = 21) +
scale_fill_brewer(palette = "Set2") +
theme_bw() + theme(panel.grid = element_blank(), axis.text = element_text(color = "black")) +
ylab("Spatial streamflow heterogeneity (percent difference)") + xlab("Water availability (percentile)") +
guides(fill = guide_legend(title = "Basin", override.aes = list(size = 5), order = 1), size = guide_legend(title = "Number of sites", order = 2)) +
geom_abline(intercept = 0, slope = 0, linetype = "dashed")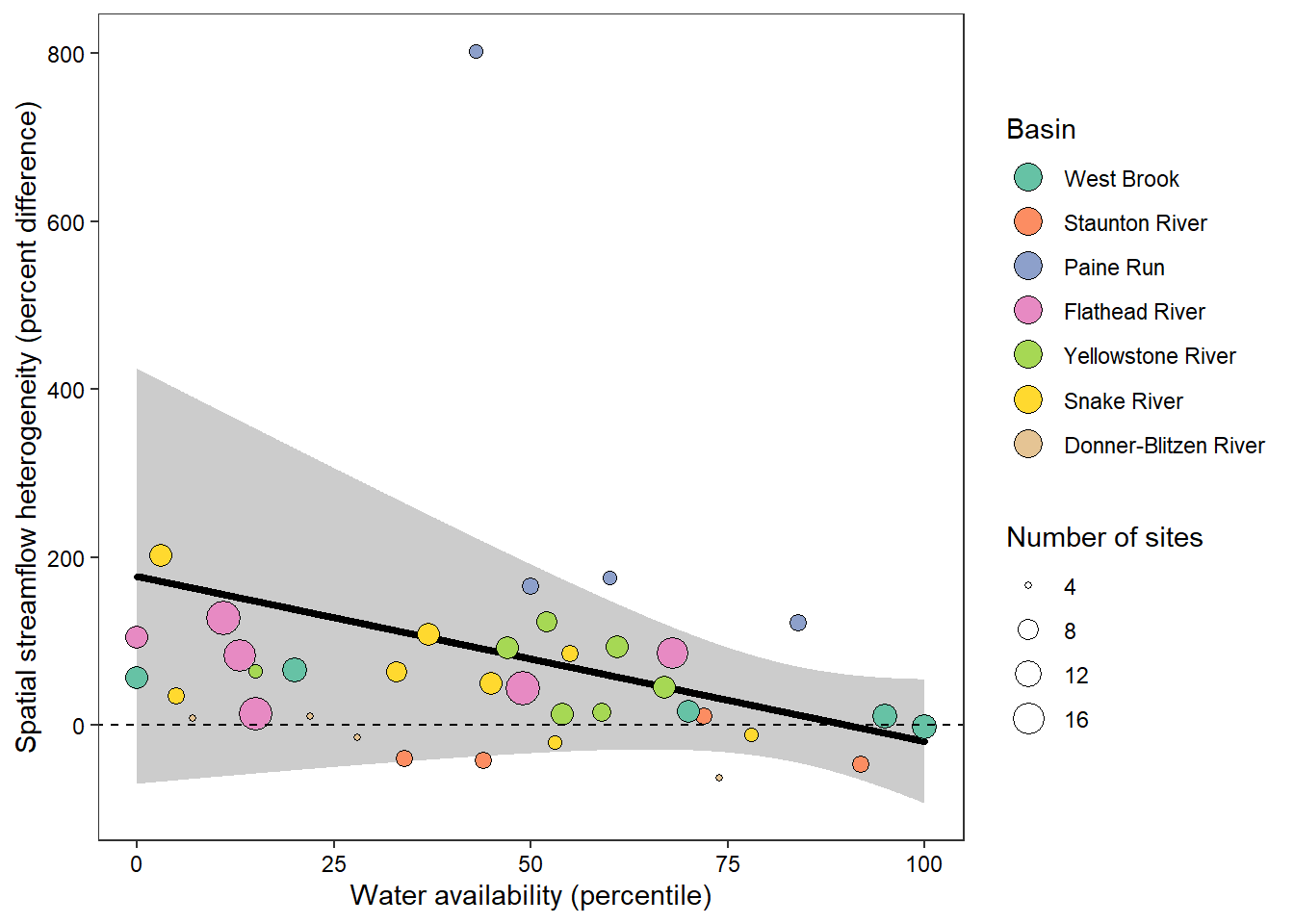
FLOW REGIME: Spatial variation (CV) in the time series distance between each little g and corresponding big G (CV of TSdist)
Some data manipulation
# define basin-years to keep
keepyears <- bind_rows(
tibble(basin = "West Brook", WaterYear = c(2020:2024)),
tibble(basin = "Paine Run", WaterYear = c(2019:2022)),
tibble(basin = "Staunton River", WaterYear = c(2019:2022)),
tibble(basin = "Flathead", WaterYear = c(2018:2024)),
tibble(basin = "Shields River", WaterYear = c(2016:2020,2022:2024)),
tibble(basin = "Snake River", WaterYear = c(2016:2024)),
tibble(basin = "Donner Blitzen", WaterYear = c(2016:2024)),
) %>% mutate(keep = "yes")
# calculate mean and cv of among little g time series distances
mydat <- dat_clean %>%
filter(Month %in% c(7:9)) %>%
left_join(dat_clean_big %>%
filter(Month %in% c(7:9)) %>%
select(basin, WaterYear, Yield_mm, logYield) %>%
rename("bigYield_mm" = "Yield_mm", "biglogYield" = "logYield")) %>%
group_by(basin, site_name, WaterYear) %>%
summarize(tsdist = EuclideanDistance(Yield_mm, bigYield_mm),
tsdist_logvals = EuclideanDistance(logYield, biglogYield)) %>%
ungroup() %>%
group_by(basin, WaterYear) %>%
summarize(mean_tsd = mean(tsdist),
mean_tsdlog = mean(tsdist_logvals),
cv_tsd = sd(tsdist) / mean(tsdist),
cv_tsdlog = sd(tsdist_logvals) / mean(tsdist_logvals),
nsites = n()) %>%
ungroup() %>%
left_join(wateravail %>% select(basin, WaterYear, totalyield:tyz_sum_perc)) %>%
left_join(keepyears) %>% filter(keep == "yes") %>%
mutate(basin = ifelse(basin == "Shields River", "Yellowstone River",
ifelse(basin == "Flathead", "Flathead River",
ifelse(basin == "Donner Blitzen", "Donner-Blitzen River", basin)))) %>%
mutate(basin = factor(basin, levels = c("West Brook", "Staunton River", "Paine Run",
"Flathead River", "Yellowstone River", "Snake River", "Donner-Blitzen River")))
mydat# A tibble: 38 × 15
basin WaterYear mean_tsd mean_tsdlog cv_tsd cv_tsdlog nsites site_name
<fct> <dbl> <dbl> <dbl> <dbl> <dbl> <int> <chr>
1 Donner-Blit… 2019 14.1 15.8 0.0922 0.135 4 Donner B…
2 Donner-Blit… 2020 9.32 17.1 0.115 0.0716 4 Donner B…
3 Donner-Blit… 2021 4.04 10.3 0.199 0.177 4 Donner B…
4 Donner-Blit… 2022 11.2 21.8 0.144 0.122 4 Donner B…
5 Flathead Ri… 2018 47.3 29.9 0.235 0.515 18 North Fo…
6 Flathead Ri… 2019 64.2 34.6 0.658 0.355 19 North Fo…
7 Flathead Ri… 2020 131. 50.3 0.296 0.629 19 North Fo…
8 Flathead Ri… 2021 67.1 38.3 0.447 0.583 17 North Fo…
9 Flathead Ri… 2022 164. 43.4 0.473 0.391 16 North Fo…
10 Flathead Ri… 2023 21.1 25.5 0.415 0.731 9 North Fo…
# ℹ 28 more rows
# ℹ 7 more variables: totalyield <dbl>, totalyield_z <dbl>,
# totalyield_sum <dbl>, totalyield_sum_z <dbl>, tyz_perc <dbl>,
# tyz_sum_perc <dbl>, keep <chr>#
# mydat %>%
# ggplot(aes(x = tyz_sum_perc, y = mean_tsd)) +
# geom_point(aes(fill = basin, size = nsites), shape = 21) +
# scale_fill_brewer(palette = "Set2") +
# theme_bw() + theme(panel.grid = element_blank(), axis.text = element_text(color = "black")) +
# ylab("Mean time series distance") + xlab("Water availability (percentile)") +
# geom_smooth(method = "lm") +
# guides(fill = guide_legend(title = "Basin", override.aes = list(size = 5), order = 1), size = guide_legend(title = "Number of sites", order = 2)) +
# geom_abline(intercept = 0, slope = 0, linetype = "dashed")
#
# mydat %>%
# ggplot(aes(x = tyz_sum_perc, y = mean_tsdlog)) +
# geom_point(aes(fill = basin, size = nsites), shape = 21) +
# scale_fill_brewer(palette = "Set2") +
# theme_bw() + theme(panel.grid = element_blank(), axis.text = element_text(color = "black")) +
# ylab("Mean time series distance (log vals)") + xlab("Water availability (percentile)") +
# geom_smooth(method = "lm") +
# guides(fill = guide_legend(title = "Basin", override.aes = list(size = 5), order = 1), size = guide_legend(title = "Number of sites", order = 2)) +
# geom_abline(intercept = 0, slope = 0, linetype = "dashed")
#
# mydat %>%
# ggplot(aes(x = tyz_sum_perc, y = cv_tsd)) +
# geom_point(aes(fill = basin, size = nsites), shape = 21) +
# scale_fill_brewer(palette = "Set2") +
# theme_bw() + theme(panel.grid = element_blank(), axis.text = element_text(color = "black")) +
# ylab("CV time series distance") + xlab("Water availability (percentile)") +
# geom_smooth(method = "lm") +
# guides(fill = guide_legend(title = "Basin", override.aes = list(size = 5), order = 1), size = guide_legend(title = "Number of sites", order = 2)) +
# geom_abline(intercept = 0, slope = 0, linetype = "dashed")
#
# mydat %>%
# ggplot(aes(x = tyz_sum_perc, y = cv_tsdlog)) +
# geom_point(aes(fill = basin, size = nsites), shape = 21) +
# scale_fill_brewer(palette = "Set2") +
# theme_bw() + theme(panel.grid = element_blank(), axis.text = element_text(color = "black")) +
# ylab("CV time series distance (log vals)") + xlab("Water availability (percentile)") +
# geom_smooth(method = "lm") +
# guides(fill = guide_legend(title = "Basin", override.aes = list(size = 5), order = 1), size = guide_legend(title = "Number of sites", order = 2)) +
# geom_abline(intercept = 0, slope = 0, linetype = "dashed")Show simple linear model summary, weighted by number of sites
summary(lm(cv_tsdlog ~ tyz_sum_perc, data = mydat, weights = nsites))
Call:
lm(formula = cv_tsdlog ~ tyz_sum_perc, data = mydat, weights = nsites)
Weighted Residuals:
Min 1Q Median 3Q Max
-0.73316 -0.33889 -0.03313 0.20782 1.16732
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 0.5405537 0.0447271 12.086 3.13e-14 ***
tyz_sum_perc -0.0036553 0.0008699 -4.202 0.000167 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 0.4393 on 36 degrees of freedom
Multiple R-squared: 0.3291, Adjusted R-squared: 0.3104
F-statistic: 17.66 on 1 and 36 DF, p-value: 0.0001665Show distribution of spatial streamflow heterogeneity by basin. Lots of structuring by basin, driven in large part by Staunton and Donner-Blitzen Rivers.
par(mar = c(9,5,0.5,0.5))
boxplot(cv_tsdlog ~ basin, data = mydat, ylab = "Spatial CV time series distance\n(log values)", xlab = "", las = 2, col = mycols)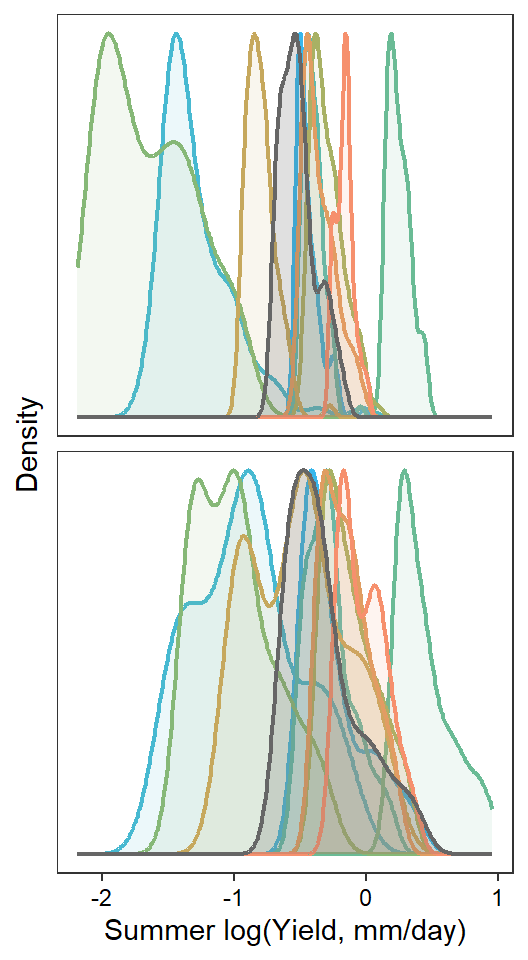
Use a random slope/random intercept mixed effects model to estimate the among-basin mean effect of regional water availability on spatial streamflow heterogeneity.
Notes:
mydat <- mydat %>% mutate(z_tyz_sum_perc = scale(tyz_sum_perc))
lmod <- lmer(cv_tsdlog ~ z_tyz_sum_perc + (1 + z_tyz_sum_perc | basin), data = mydat)
summary(lmod)Linear mixed model fit by REML. t-tests use Satterthwaite's method [
lmerModLmerTest]
Formula: cv_tsdlog ~ z_tyz_sum_perc + (1 + z_tyz_sum_perc | basin)
Data: mydat
REML criterion at convergence: -40.3
Scaled residuals:
Min 1Q Median 3Q Max
-2.07297 -0.52190 -0.07904 0.53009 1.90653
Random effects:
Groups Name Variance Std.Dev. Corr
basin (Intercept) 0.0168046 0.12963
z_tyz_sum_perc 0.0007697 0.02774 -1.00
Residual 0.0108559 0.10419
Number of obs: 38, groups: basin, 7
Fixed effects:
Estimate Std. Error df t value Pr(>|t|)
(Intercept) 0.31872 0.05210 5.87943 6.117 0.00094 ***
z_tyz_sum_perc -0.07644 0.02173 9.57196 -3.519 0.00594 **
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Correlation of Fixed Effects:
(Intr)
z_tyz_sm_pr -0.481
optimizer (nloptwrap) convergence code: 0 (OK)
boundary (singular) fit: see help('isSingular')Get p-values for global slope and intercept: (doesn’t to run in Quarto…works fine in R)
coef(summary(as_lmerModLmerTest(lmod))) Estimate Std. Error df t value Pr(>|t|)
(Intercept) 0.31871978 0.05210474 5.879432 6.116906 0.0009400863
z_tyz_sum_perc -0.07644414 0.02172625 9.571956 -3.518516 0.0059364707Plot relationship between spatial streamflow heterogeneity and regional water availability with global (among-population mean) regression line.
# get predicted values and 95% credible interval
effects_tyz <- effects::effect(term = "z_tyz_sum_perc", mod = as_lmerModLmerTest(lmod), xlevels = list(z_tyz_sum_perc = seq(min(mydat$z_tyz_sum_perc), max(mydat$z_tyz_sum_perc), length.out = 1000)), se = list(level = 0.95))
x_tyz <- as_tibble(effects_tyz) %>% mutate(tyz_sum_perc = (z_tyz_sum_perc * attr(mydat$z_tyz_sum_perc, "scaled:scale")) + attr(mydat$z_tyz_sum_perc, "scaled:center"))
# trim data for panel labesl
mydat_labs <- bind_rows(mydat %>% filter(basin == "West Brook", WaterYear %in% c(2020,2021)),
mydat %>% filter(basin == "Snake River", WaterYear %in% c(2021,2022))) %>%
mutate(labs = c("b", "c", "d", "e"))
# plot
randiffplot <- ggplot() +
geom_ribbon(data = x_tyz, aes(x = tyz_sum_perc, ymin = lower, ymax = upper), fill = "grey80") +
geom_line(data = x_tyz, aes(x = tyz_sum_perc, y = fit), color = "black", size = 1.25, lineend = "round") +
geom_point(data = mydat, aes(x = tyz_sum_perc, y = cv_tsdlog, fill = basin, size = nsites), shape = 21) +
scale_fill_brewer(palette = "Set2") +
geom_text(data = mydat_labs, aes(x = tyz_sum_perc, y = cv_tsdlog, label = labs), size = 3) +
theme_bw() + theme(panel.grid = element_blank(), axis.text = element_text(color = "black")) +
ylab("Spatial CV time series distance") + xlab("Water availability (percentile)") +
guides(fill = guide_legend(title = "Basin", override.aes = list(size = 5), order = 1), size = guide_legend(title = "Number of sites", order = 2)) +
geom_abline(intercept = 0, slope = 0, linetype = "dashed") +
annotate("text", x = Inf, y = Inf, hjust = 1.1, vjust = 1.1, fontface = "italic",
label = paste("p = ", round(coef(summary(as_lmerModLmerTest(lmod)))[2,5], digits = 3)))
randiffplot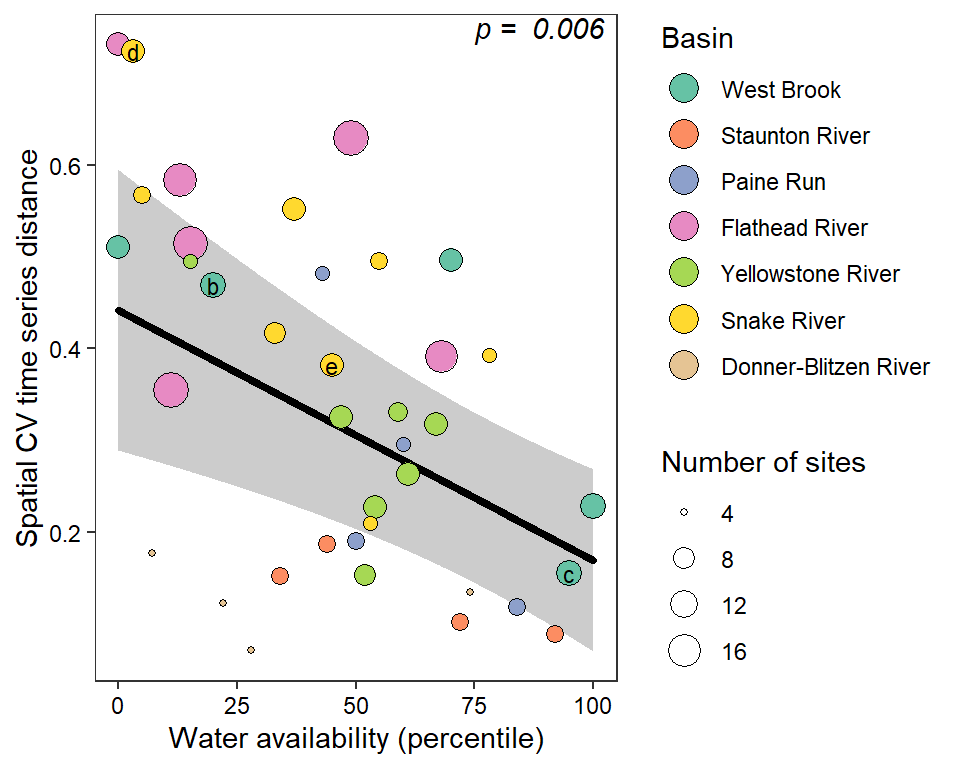
randiffplot2 <- randiffplot
# write to file
# jpeg("C:/Users/jbaldock/OneDrive - DOI/Documents/USGS/EcoDrought/EcoDrought Working/Presentation figs/EcoD_RangeDiff_allsites2.jpg", width = 4.75, height = 5, units = "in", res = 1000)
# randiffplot
# dev.off()Use rptR to decompose variance in spatial streamflow heterogeneity into fixed (regional water availability) and random (basin) effect sources:
rmod <- rptGaussian(cv_tsdlog ~ z_tyz_sum_perc + (1 + z_tyz_sum_perc | basin), data = mydat, grname = c("basin", "Fixed"), ratio = TRUE, adjusted = FALSE, nboot = 1000)Bootstrap Progress:print(rmod)
Repeatability estimation using the lmm method
Repeatability for basin
R = 0.512
SE = 0.172
CI = [0.099, 0.769]
P = 0.000678 [LRT]
NA [Permutation]
Repeatability for Fixed
R = 0.171
SE = 0.105
CI = [0.034, 0.451]
P = NA [LRT]
NA [Permutation]rmod$modLinear mixed model fit by REML ['lmerMod']
Formula: cv_tsdlog ~ z_tyz_sum_perc + (1 + z_tyz_sum_perc | basin)
Data: data
REML criterion at convergence: -40.3205
Random effects:
Groups Name Std.Dev. Corr
basin (Intercept) 0.12963
z_tyz_sum_perc 0.02774 -1.00
Residual 0.10419
Number of obs: 38, groups: basin, 7
Fixed Effects:
(Intercept) z_tyz_sum_perc
0.31872 -0.07644
optimizer (nloptwrap) convergence code: 0 (OK) ; 0 optimizer warnings; 1 lme4 warnings plot(rmod, grname = "basin")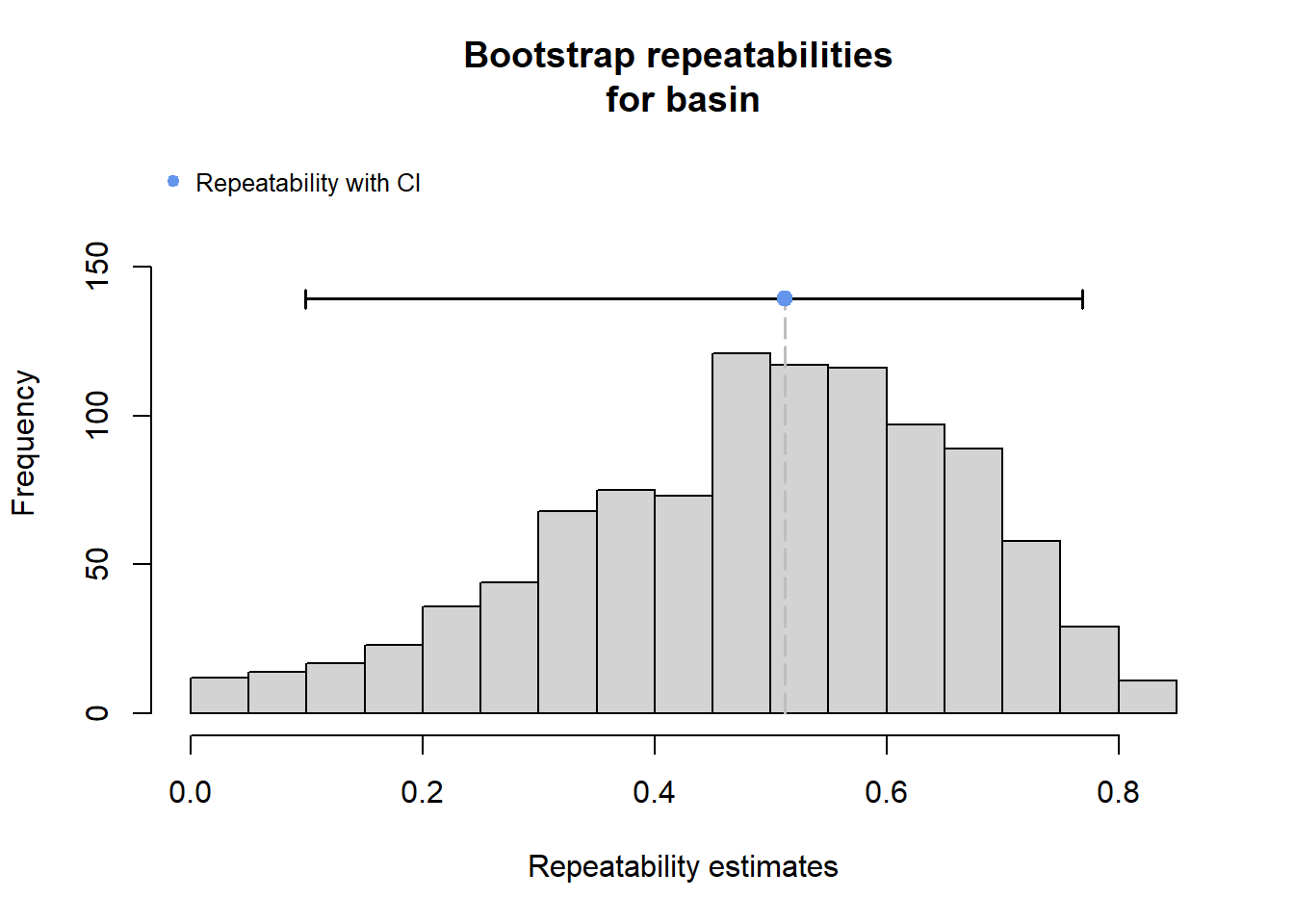
plot(rmod, grname = "Fixed")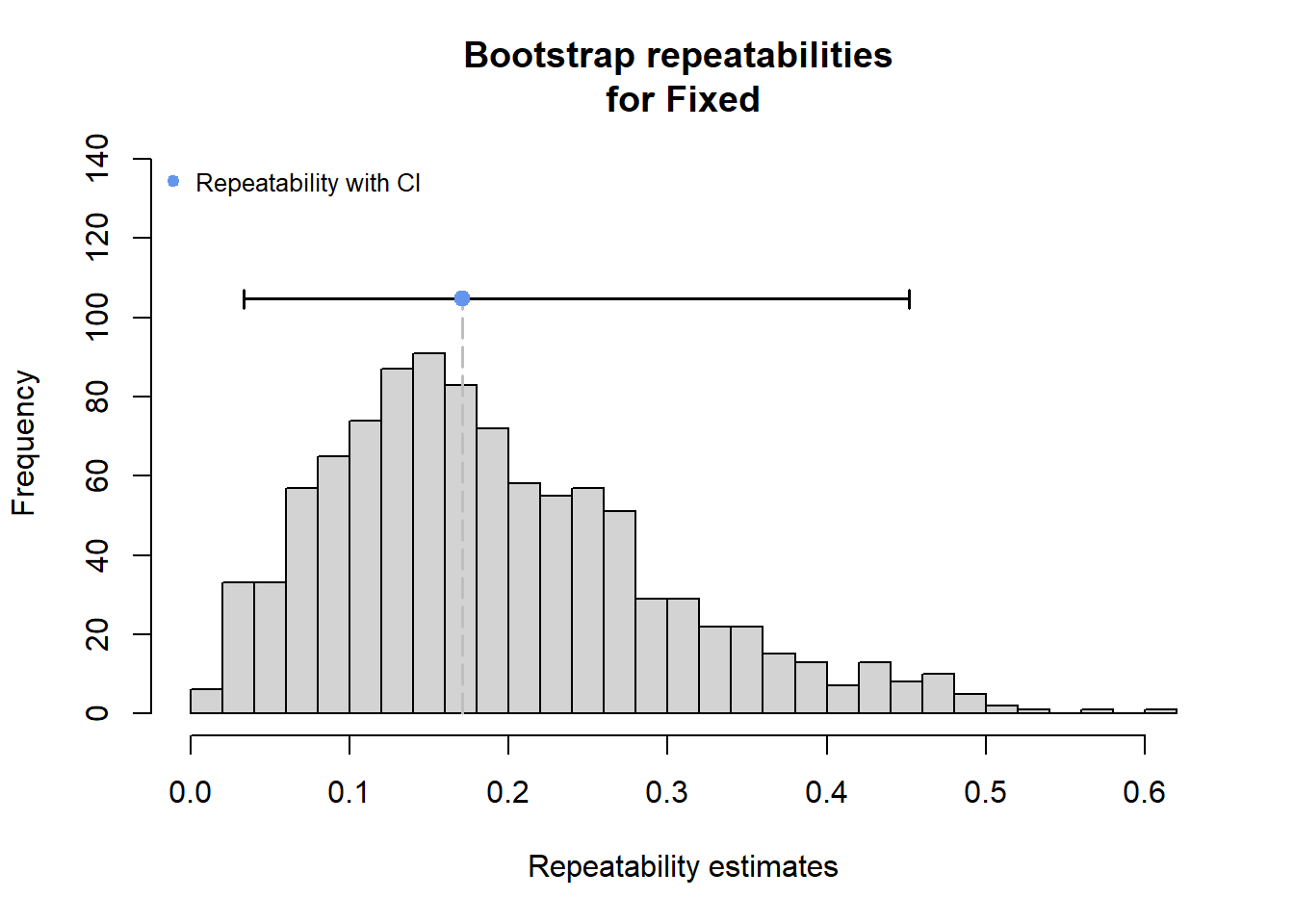
The strong effect of basin is largely driven by Staunton and Donner-Blitzen Rivers. Without those basins, random effect variance shrinks and fixed effect variance expands considerably. Much of this pattern is likely due to low sample sizes (few headwater gages in these basins, particularly in the Donner-Blitzen)
rmod <- rptGaussian(cv_tsdlog ~ z_tyz_sum_perc + (1 + z_tyz_sum_perc | basin), data = mydat %>% filter(!basin %in% c("Staunton River", "Donner-Blitzen River")), grname = c("basin", "Fixed"), ratio = TRUE, adjusted = FALSE, nboot = 1000)Bootstrap Progress:print(rmod)
Repeatability estimation using the lmm method
Repeatability for basin
R = 0.101
SE = 0.117
CI = [0, 0.408]
P = 0.852 [LRT]
NA [Permutation]
Repeatability for Fixed
R = 0.455
SE = 0.128
CI = [0.186, 0.691]
P = NA [LRT]
NA [Permutation]2020/2021 summer flow distributions
bas <- "West Brook"
orderr <- wborder
wtryrs <- c(2020,2021)
# filter data
tempdat <- dat_clean %>%
filter(basin == bas, !is.na(logYield), Month %in% c(7:9), WaterYear %in% wtryrs) %>%
mutate(site_name = factor(site_name, levels = orderr))
nsites <- length(unique(tempdat$site_name))
tempdat_big <- dat_clean_big %>% filter(basin == bas, !is.na(logYield), Month %in% c(7:9), WaterYear %in% unique(tempdat$WaterYear))
# annual
pann <- ggplot() +
geom_density(data = tempdat, aes(x = logYield, y = ..scaled.., color = site_name, fill = site_name), size = 0.8) +
scale_color_manual(values = cet_pal(nsites, name = "i1")) +
scale_fill_manual(values = alpha(cet_pal(nsites, name = "i1"), 0.1)) +
geom_density(data = tempdat_big, aes(x = logYield, y = ..scaled..), color = "grey40", fill = alpha("grey40", 0.2), size = 0.8) +
xlab("Summer log(Yield, mm/day)") + ylab("Density") +
theme_bw() + theme(panel.grid.major = element_blank(), panel.grid.minor = element_blank(),
axis.text.y = element_blank(), axis.ticks.y = element_blank(),
axis.text = element_text(color = "black"), legend.position = "none",
strip.background = element_blank(), strip.text = element_blank()) +
facet_wrap(~factor(WaterYear, levels = as.numeric(unlist(pedat %>% arrange(totalyield_sum_z) %>% select(WaterYear)))), ncol = 1)
print(pann)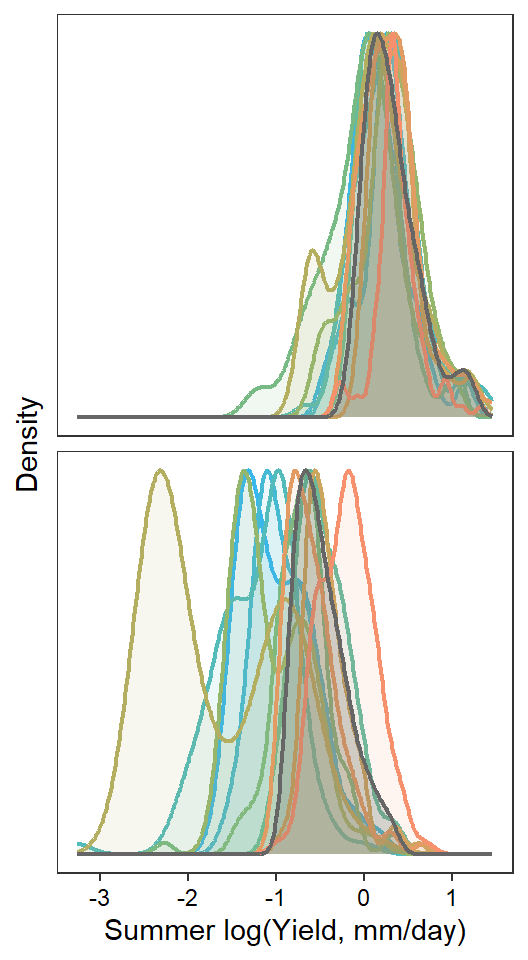
# jpeg("C:/Users/jbaldock/OneDrive - DOI/Documents/USGS/EcoDrought/EcoDrought Working/Presentation figs/EcoD_summerdensity_WB_annual.jpg", width = 2.75, height = 5, units = "in", res = 1000)
# pann
# dev.off()2020/2021 summer flow distributions
bas <- "West Brook"
orderr <- wborder
wtryrs <- c(2020,2021)
# sheds and network
mysheds <- vect("C:/Users/jbaldock/OneDrive - DOI/Documents/USGS/EcoDrought/EcoDrought Working/EcoDrought-Analysis/Watershed Delineation/Watersheds/Mass_Watersheds.shp")
mysheds <- mysheds[mysheds$site_id == "WBR",]
mynet <- vect("C:/Users/jbaldock/OneDrive - DOI/Documents/USGS/EcoDrought/EcoDrought Working/EcoDrought-Analysis/Watershed Delineation/Streams/Mass_Streams.shp")
crs(mynet) <- crs(mysheds)
mynet <- crop(mynet, mysheds)
# get lakes
lakes <- get_waterbodies(AOI = siteinfo_sp %>% filter(site_name == "West Brook NWIS"), buffer = 10000)
lakes <- lakes %>% filter(gnis_name %in% c("Northampton Reservoir Upper", "Northampton Reservoir"))
# little g points
mylittleg <- siteinfo_sp %>% filter(site_name %in% wborder) %>% mutate(site_name = factor(site_name, levels = wborder))
# filter data
tempdat <- dat_clean %>%
filter(basin == bas, !is.na(logYield), Month %in% c(7:9)) %>%
mutate(site_name = factor(site_name, levels = orderr))
nsites <- length(unique(tempdat$site_name))
tempdat_big <- dat_clean_big %>% filter(basin == bas, !is.na(logYield), Month %in% c(7:9), WaterYear %in% unique(tempdat$WaterYear))
# calculate variability for reference gage
varbig <- tempdat_big %>%
group_by(WaterYear) %>%
summarize(bigrange = range(logYield)[2]-range(logYield)[1],
bigsd = sd(logYield),
bigvar = var(logYield)) %>%
ungroup()
# calculate total summer water availability from reference gage
#summerflow <- tempdat_big %>% group_by(WaterYear) %>% summarize(summeryield = sum(Yield_mm), summeryield_log = log(sum(Yield_mm))) %>% ungroup()
#wateravail2 <- wateravail %>% select(basin, WaterYear, totalyield, totalyield_z)
# calculate relative variation
pedat <- tempdat %>%
group_by(basin, WaterYear) %>%
summarize(nsites = length(unique(site_name)),
littlerange = range(logYield)[2]-range(logYield)[1],
littlesd = sd(logYield),
littlevar = var(logYield)) %>%
ungroup() %>%
left_join(varbig) %>%
mutate(pe_range = ((littlerange-bigrange)/bigrange),
pe_sd = ((littlesd-bigsd)/bigsd),
pe_var = ((littlevar-bigvar)/bigvar)) %>%
left_join(wateravail %>% select(basin, WaterYear, totalyield, totalyield_z, totalyield_sum, totalyield_sum_z, tyz_perc, tyz_sum_perc)) %>%
filter(WaterYear %in% wtryrs) %>%
mutate(wylab = substr(WaterYear, 3, 4)) %>%
arrange(totalyield_sum_z)
# calculate annual median summer flow
annmed <- tempdat %>%
#filter(WaterYear %in% c(lowyr, highyr)) %>%
group_by(site_name, WaterYear) %>%
summarize(medlogYield = median(logYield, na.rm = TRUE)) %>%
ungroup()
# arrange years by total annual yield
wtryrs_arranged <- as.numeric(unlist(pedat %>% select(WaterYear)))
# plot it
plotlist_wb <- list()
for(i in 1:length(wtryrs_arranged)) {
mylittleg <- siteinfo_sp %>% filter(site_name %in% orderr) %>% left_join(annmed %>% filter(WaterYear == wtryrs_arranged[i]))
mylittleg_sheds <- sheds %>% filter(site_name %in% orderr) %>% left_join(annmed %>% filter(WaterYear == wtryrs_arranged[i])) %>% arrange(desc(area_sqmi))
plotlist_wb[[i]] <- local({
i <- i
ggplot() +
geom_sf(data = st_as_sf(mysheds), color = "black", fill = "white", linewidth = 0.4) +
geom_sf(data = mylittleg_sheds, aes(fill = medlogYield), color = "black") +
scale_fill_viridis(option = "G", direction = 1, limits = range(annmed$medlogYield), na.value = "grey") +
geom_sf(data = st_as_sf(mynet), color = "white", linewidth = 1, lineend = "round") +
geom_sf(data = st_as_sf(mynet), color = "royalblue4", linewidth = 0.6, lineend = "round") +
geom_sf(data = lakes, color = "white", fill = "lightskyblue1", linewidth = 0.7) +
geom_sf(data = lakes, color = "royalblue4", fill = "lightskyblue1", linewidth = 0.5) +
geom_sf(data = mylittleg, shape = 21, fill = "white", size = 2) +
labs(fill = "Median\nsummer\nlog(Yield)") + #annotation_scale() +
coord_sf(xlim = range(st_coordinates(mylittleg_sheds)[,1]), ylim = range(st_coordinates(mylittleg_sheds)[,2])) +
theme_bw() + theme(axis.title.x = element_blank(), axis.title.y = element_blank(), legend.position = "none", axis.text = element_blank()) +
theme_void() + scale_x_continuous(expand = c(0.003, 0.003)) + scale_y_continuous(expand = c(0.002, 0.002))
#annotate("label", x = Inf, y = Inf, label = paste(pedat$WaterYear[i], " (", pedat$tyz_sum_perc[i], "%)", sep = ""), vjust = 1.15, hjust = 1.05, size = 5)
})
}
p <- ggarrange(plotlist = plotlist_wb, common.legend = TRUE, legend = "right", nrow = 2)
print(p)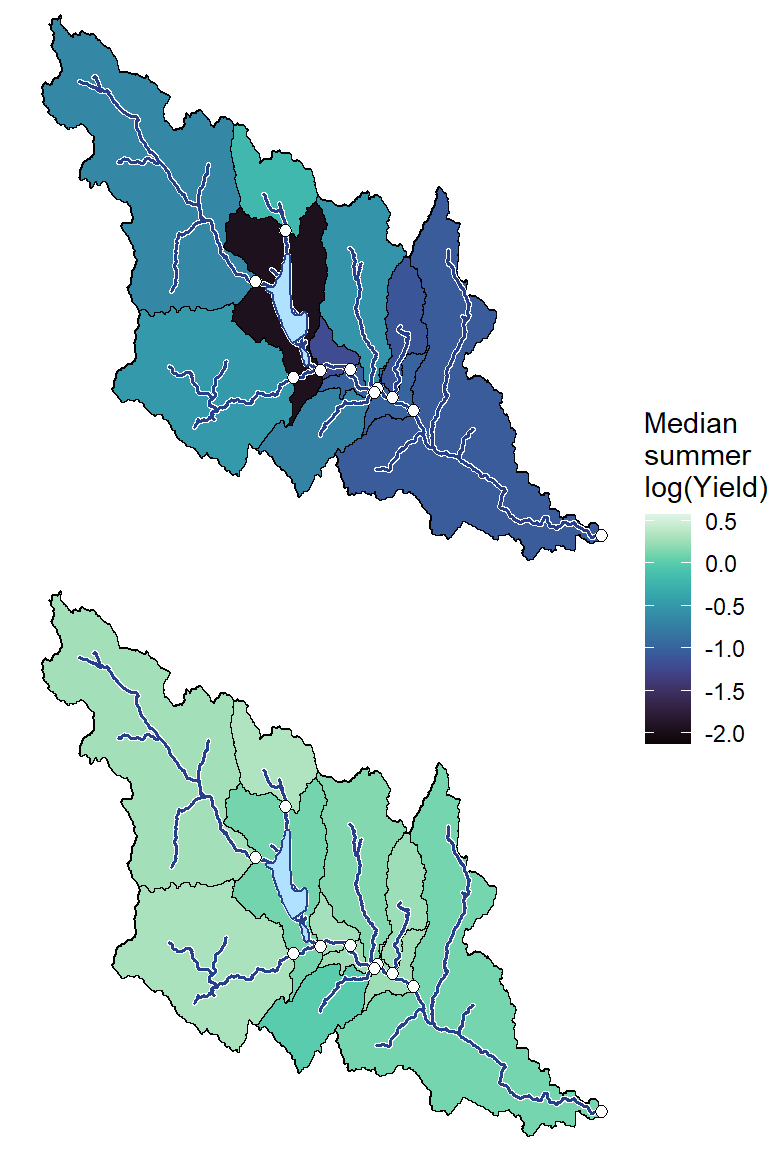
# jpeg("C:/Users/jbaldock/OneDrive - DOI/Documents/USGS/EcoDrought/EcoDrought Working/Presentation figs/EcoD_summermedianmap_WB_annual.jpg", width = 4, height = 6, units = "in", res = 1000)
# p
# dev.off()2021/2022 summer flow distributions
bas <- "Snake River"
orderr <- snakeorder
wtryrs <- c(2021,2022)
# filter data
tempdat <- dat_clean %>%
filter(basin == bas, !is.na(logYield), Month %in% c(7:9), WaterYear %in% wtryrs) %>%
mutate(site_name = factor(site_name, levels = orderr))
nsites <- length(unique(tempdat$site_name))
tempdat_big <- dat_clean_big %>% filter(basin == bas, !is.na(logYield), Month %in% c(7:9), WaterYear %in% unique(tempdat$WaterYear))
# annual
pann <- ggplot() +
geom_density(data = tempdat, aes(x = logYield, y = ..scaled.., color = site_name, fill = site_name), size = 0.8) +
scale_color_manual(values = cet_pal(nsites, name = "i1")) +
scale_fill_manual(values = alpha(cet_pal(nsites, name = "i1"), 0.1)) +
geom_density(data = tempdat_big, aes(x = logYield, y = ..scaled..), color = "grey40", fill = alpha("grey40", 0.2), size = 0.8) +
xlab("Summer log(Yield, mm/day)") + ylab("Density") +
theme_bw() + theme(panel.grid.major = element_blank(), panel.grid.minor = element_blank(),
axis.text.y = element_blank(), axis.ticks.y = element_blank(),
axis.text = element_text(color = "black"), legend.position = "none",
strip.background = element_blank(), strip.text = element_blank()) +
facet_wrap(~factor(WaterYear, levels = as.numeric(unlist(pedat %>% arrange(totalyield_sum_z) %>% select(WaterYear)))), ncol = 1)
print(pann)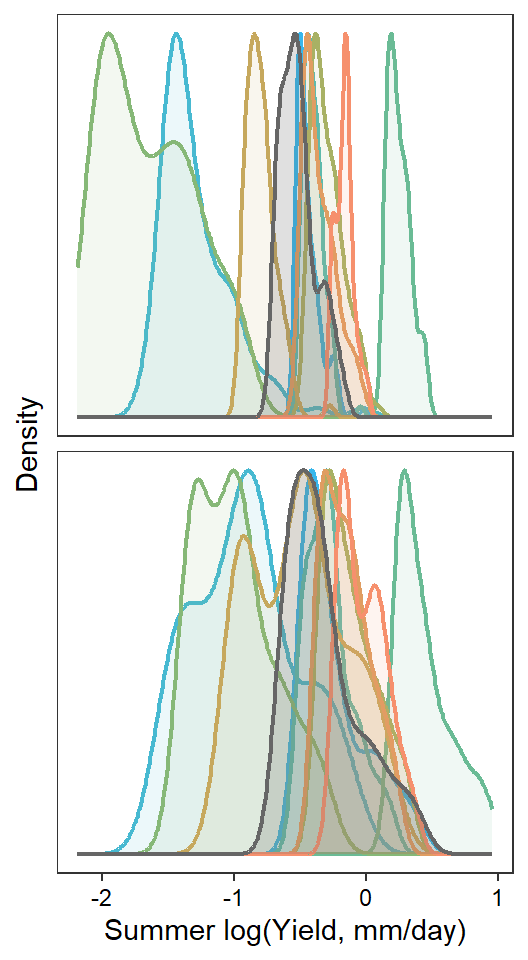
# jpeg("C:/Users/jbaldock/OneDrive - DOI/Documents/USGS/EcoDrought/EcoDrought Working/Presentation figs/EcoD_summerdensity_Snake_annual.jpg", width = 2.75, height = 5, units = "in", res = 1000)
# pann
# dev.off()2022/2022 summer flow distributions
bas <- "Snake River"
orderr <- snakeorder
wtryrs <- c(2021,2022)
mysheds <- vect("C:/Users/jbaldock/OneDrive - DOI/Documents/USGS/EcoDrought/EcoDrought Working/EcoDrought-Analysis/Watershed Delineation/Watersheds/Snake_Watersheds.shp")
mysheds <- mysheds[mysheds$site_id == "SP11",]
mynet <- vect("C:/Users/jbaldock/OneDrive - DOI/Documents/USGS/EcoDrought/EcoDrought Working/EcoDrought-Analysis/Watershed Delineation/Streams/Snake_Streams.shp")
crs(mynet) <- crs(mysheds)
mynet <- crop(mynet, mysheds)
# get lakes
lakes <- get_waterbodies(AOI = siteinfo_sp %>% filter(site_name == "Spread Creek Dam"), buffer = 100000)
lakes <- st_transform(lakes, crs(mysheds))
lakes <- st_intersection(lakes, st_as_sf(mysheds))
lakes <- lakes %>% filter(gnis_name %in% c("Leidy Lake"))
# points
mylittleg <- siteinfo_sp %>% filter(site_name %in% snakeorder) %>% mutate(site_name = factor(site_name, levels = snakeorder))
# edit geometry to reduce overlap
st_geometry(mylittleg)[mylittleg$site_name == "SF Spread Creek Lower NWIS"] <- st_point(c(-110.32226, 43.76118))
st_geometry(mylittleg)[mylittleg$site_name == "NF Spread Creek Lower"] <- st_point(c(-110.3199, 43.766533))
st_geometry(mylittleg)[mylittleg$site_name == "Grizzly Creek"] <- st_point(c(-110.23289, 43.77433))
st_geometry(mylittleg)[mylittleg$site_name == "NF Spread Creek Upper"] <- st_point(c(-110.23405, 43.77227))
st_geometry(mylittleg)[mylittleg$site_name == "SF Spread Creek Upper"] <- st_point(c(-110.31475, 43.73661))
# filter data
tempdat <- dat_clean %>%
filter(basin == bas, !is.na(logYield), Month %in% c(7:9)) %>%
mutate(site_name = factor(site_name, levels = orderr))
nsites <- length(unique(tempdat$site_name))
tempdat_big <- dat_clean_big %>% filter(basin == bas, !is.na(logYield), Month %in% c(7:9), WaterYear %in% unique(tempdat$WaterYear))
# calculate variability for reference gage
varbig <- tempdat_big %>%
group_by(WaterYear) %>%
summarize(bigrange = range(logYield)[2]-range(logYield)[1],
bigsd = sd(logYield),
bigvar = var(logYield)) %>%
ungroup()
# calculate total summer water availability from reference gage
#summerflow <- tempdat_big %>% group_by(WaterYear) %>% summarize(summeryield = sum(Yield_mm), summeryield_log = log(sum(Yield_mm))) %>% ungroup()
#wateravail2 <- wateravail %>% select(basin, WaterYear, totalyield, totalyield_z)
# calculate relative variation
pedat <- tempdat %>%
group_by(basin, WaterYear) %>%
summarize(nsites = length(unique(site_name)),
littlerange = range(logYield)[2]-range(logYield)[1],
littlesd = sd(logYield),
littlevar = var(logYield)) %>%
ungroup() %>%
left_join(varbig) %>%
mutate(pe_range = ((littlerange-bigrange)/bigrange),
pe_sd = ((littlesd-bigsd)/bigsd),
pe_var = ((littlevar-bigvar)/bigvar)) %>%
left_join(wateravail %>% select(basin, WaterYear, totalyield, totalyield_z, totalyield_sum, totalyield_sum_z, tyz_perc, tyz_sum_perc)) %>%
filter(WaterYear %in% wtryrs) %>%
mutate(wylab = substr(WaterYear, 3, 4)) %>%
arrange(totalyield_sum_z)
# calculate annual median summer flow
annmed <- tempdat %>%
#filter(WaterYear %in% c(lowyr, highyr)) %>%
group_by(site_name, WaterYear) %>%
summarize(medlogYield = median(logYield, na.rm = TRUE)) %>%
ungroup()
# arrange years by total annual yield
wtryrs_arranged <- as.numeric(unlist(pedat %>% select(WaterYear)))
# plot it
plotlist_wb <- list()
for(i in 1:length(wtryrs_arranged)) {
mylittleg <- siteinfo_sp %>% filter(site_name %in% orderr) %>% left_join(annmed %>% filter(WaterYear == wtryrs_arranged[i]))
mylittleg_sheds <- sheds %>% filter(site_name %in% orderr) %>% left_join(annmed %>% filter(WaterYear == wtryrs_arranged[i])) %>% arrange(desc(area_sqmi))
plotlist_wb[[i]] <- local({
i <- i
ggplot() +
geom_sf(data = st_as_sf(mysheds), color = "black", fill = "white", linewidth = 0.4) +
geom_sf(data = mylittleg_sheds, aes(fill = medlogYield), color = "black") +
scale_fill_viridis(option = "G", direction = 1, limits = range(annmed$medlogYield), na.value = "grey") +
geom_sf(data = st_as_sf(mynet), color = "white", linewidth = 1, lineend = "round") +
geom_sf(data = st_as_sf(mynet), color = "royalblue4", linewidth = 0.6, lineend = "round") +
geom_sf(data = lakes, color = "white", fill = "lightskyblue1", linewidth = 0.7) +
geom_sf(data = lakes, color = "royalblue4", fill = "lightskyblue1", linewidth = 0.5) +
geom_sf(data = mylittleg, shape = 21, fill = "white", size = 2) +
labs(fill = "Median\nsummer\nlog(Yield)") + #annotation_scale() +
coord_sf(xlim = range(st_coordinates(mylittleg_sheds)[,1]), ylim = range(st_coordinates(mylittleg_sheds)[,2])) +
theme_bw() + theme(axis.title.x = element_blank(), axis.title.y = element_blank(), legend.position = "none", axis.text = element_blank()) +
theme_void() + scale_x_continuous(expand = c(0.003, 0.003)) + scale_y_continuous(expand = c(0.002, 0.002))
#annotate("label", x = Inf, y = Inf, label = paste(pedat$WaterYear[i], " (", pedat$tyz_sum_perc[i], "%)", sep = ""), vjust = 1.15, hjust = 1.05, size = 5)
})
}
p <- ggarrange(plotlist = plotlist_wb, common.legend = TRUE, legend = "right", nrow = 2)
print(p)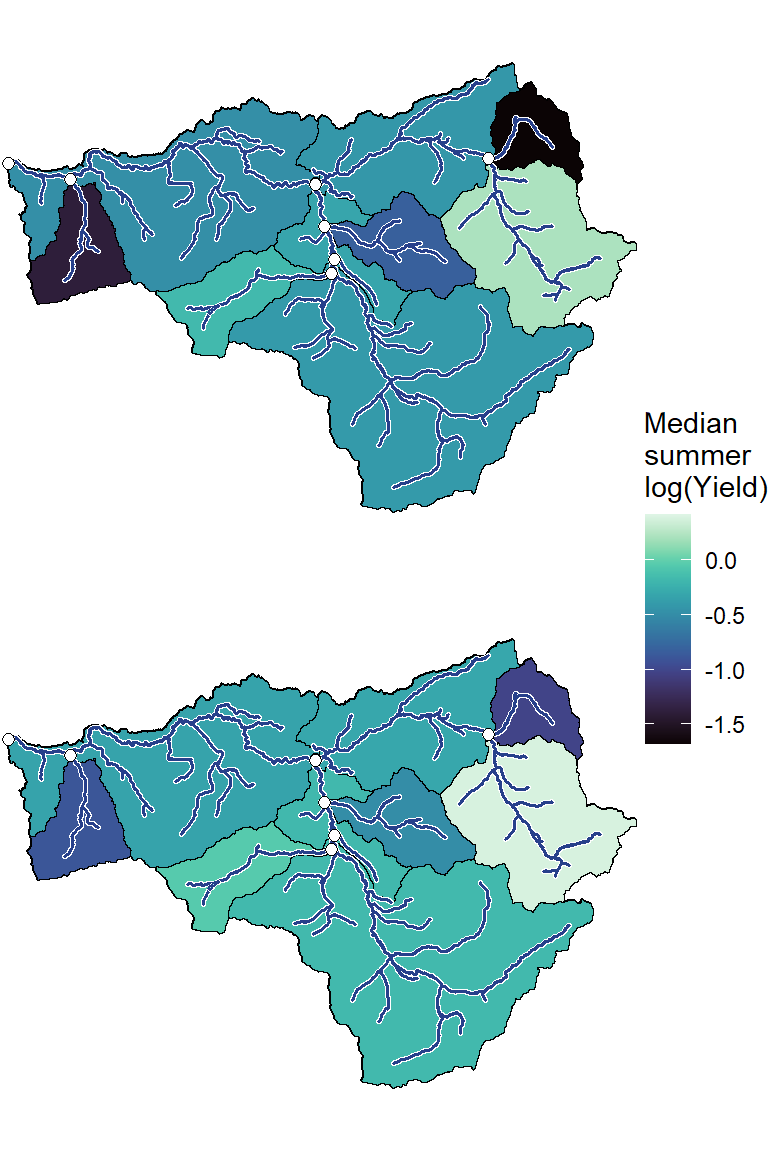
# jpeg("C:/Users/jbaldock/OneDrive - DOI/Documents/USGS/EcoDrought/EcoDrought Working/Presentation figs/EcoD_summermedianmap_Snake_annual.jpg", width = 4, height = 6, units = "in", res = 1000)
# p
# dev.off()